Syllabus
Unit I
Introduction to Computer: Definition, Computer Hardware & Computer Software
Components: Hardware – Introduction, Input devices, Output devices, Central Processing
Unit, Memory- Primary and Secondary. Software - Introduction, Types – System
and Application.
Computer Languages: Introduction, Concept of Compiler, Interpreter
&Assembler
Problem solving concept: Algorithms – Introduction, Definition,
Characteristics,
Limitations, Conditions in pseudo-code, Loops in pseudo code.
Unit II
Operating system:
Definition, Functions, Types, Classification, Elements of command based and GUI
based operating system.
Computer Network: Overview,
Types (LAN, WAN and MAN), Data
Communication, topologies.
Unit III
Internet : Overview, Architecture, Functioning,
Basic services like WWW, FTP,Telnet, Gopher etc., Search engines, E-mail, Web
Browsers.
Internet of Things (IoT): Definition, Sensors,
their types and features, Smart
Cities, Industrial Internet of Things.
Unit IV
Block chain: Introduction, overview, features,
limitations and application areas ,fundamentals of Block Chain.
Crypto currencies: Introduction , Applications
and use cases
Cloud Computing: It nature and benefits, AWS,
Google, Microsoft & IBM Services
Unit V
Emerging Technologies: Introduction, overview, features, limitations and application
areas of Augmented Reality, Virtual Reality, Grid computing, Green computing,
Big data analytics, Quantum Computing and Brain Computer Interface
UNIT I
----------
COMPUTER: AN INTRODUCTION
Definition: we can define a
computer in different perspectives like a Computer is a machine, a computer is
an electronic device, a Computer is a data processor, and a computer is a
digital device. Etc. but in a much-summarized way…
A computer is a digital device that takes data process it under some
specific program and produces some meaningful output.
Mainly computer is a digital data problem solver or action performer. It
takes data to process it on the basis of some previously loaded program (set of
instructions) and produces the desired result. A computer can’t do anything
that is not pre-loaded into it.
Like many other machines, a computer is also a system. Any system has
three main components input-process-output. As our human body, we listen from
our ear process it under our brain and when we find some result we can show the
output with the help of mouth (speak) or hand (writing). No system can work
independently. Like many other systems, computers are also a system, it takes
command, instructions, raw data, etc. with the help of specified input devices
and then processes it with a special device that is called a processor (processor
work on preloaded program) and then produces a result. It can be understood
with an example suppose that you want to find the result of 15 * 5 to do this
you can take the help of a computer. The computer takes input (15 * 5) then the
processor processes it on the basis of a table program that is preloaded and
gets the result i.e. 75. But how could you know the result so there are some
output devices which are used to show the result that is produced by the
processor? In very short we can say that a computer is a system for data
processing.
Characteristics of a computer
Speed The speed of computers is very fast. It
can perform in a few seconds the amount of work that human beings can do in an
hour. When we are talking about the speed of a computer we do not talk in terms
of seconds or even milliseconds it is nanoseconds. The computer can perform
about 3 to 4 million arithmetic operations per second. The unit of speed of the
computer is Hertz. A normal desktop computer processor speed is between 3.50 to
4.2 GHz.
Accuracy accuracy of computer is very high or in
other word we can say that if program design is very good Computer cannot do
any mistake. Basically, the accuracy of the program is depending on the
accuracy of program writing. So after a long period of time on program testing
and the debugging program becomes more accurate. The accuracy of a particular
program becomes more accurate Day by day.
Alertness Computer is a machine so it does not get
tired and hence can work for long time without creating any error or mistake.
It means that there is no different to perform one arithmetic operation 10
arithmetic operation or for thousand or millions of arithmetic operations the
result will be same because of there is no issue of tiredness like human
beings. The computer always works on full alert mode.
Versatility Modern era demands versatility from
everyone. In cricket, the all-rounder is more on the demand of the player. The
same player has also liked if the batsman is also a bowler; he is also a good
fielder. In the same way, people want to get more and more work from the same
machine. Nowadays we can perform any task with the help of a computer. we can
type, watch movies, listening songs, internet browse, download files, perform
many government-related official jobs using e-governance and so many other
useful tasks can be done using a single machine it is called versatility. A
computer is capable of performing almost any task provided that the task can be
reduced to a series of logical steps.
V.
A
computer is a digital device that takes data process it under some specific
program and produces some meaningful output.
VI.
Mainly
computer is a digital data problem solver or action performer. It takes data to
process it on the basis of some previously loaded program (set of instructions)
and produces the desired result. A computer can’t do anything that is not
pre-loaded into it.
VII.
Like
many other machines, a computer is also a system. Any system has three main
components input-process-output. As our human body, we listen from our ear
process it under our brain and when we find some result we can show the output
with the help of mouth (speak) or hand (writing). No system can work
independently. Like many other systems, computers are also a system, it takes
command, instructions, raw data, etc. with the help of specified input devices
and then processes it with a special device that is called a processor (processor
work on preloaded program) and then produces a result. It can be understood
with an example suppose that you want to find the result of 15 * 5 to do this
you can take the help of a computer. The computer takes input (15 * 5) then the
processor processes it on the basis of a table program that is preloaded and
gets the result i.e. 75. But how could you know the result so there are some
output devices which are used to show the result that is produced by the
processor? In very short we can say that a computer is a system for data
processing. A computer has a huge storage capacity. We can store millions of
libraries on a single computer. A
computer can store any amount of information because of its secondary storage.
Every piece of information can be stored as long as desired by the user and can
be recalled when required. A byte is a storage unit. Normally 1 TB (TeraByte)
hard disk is used in desktop. Later we will discuss these units in detail.
Artificial Intelligence (AI): Above characteristics belong to some
traditional computer systems nowadays modern computers come with AI. It
means that it can perform much better than previously loaded programs. An artificial
intelligence inbuilt computer can take its own decision. Google search is
based on artificial intelligence it produces the result of searching on
the basis of a particular user searching experience. This type of computer
can change the program it can modify the loaded program
Elements
of a Computer System set up:
There are
mainly five elements of a computer system.
(i) Hardware: the physical part of the computer
system that we can see, touch, and move from one place to another is called
hardware. For example mouse, keyboard, optical scanner, monitor, printer,
processor, etc.
(ii) Software: it is the part of the computer system that we cannot see but the
whole system is based on that part, we call it software. Software is mainly a
collection of programs. And the program is a set of instructions to solve any
given problem or to perform any particular job. All the work of the computer
depends on the program. The computer cannot do anything that is not already
written in the program, that is, what the computer can do. Everything is
already written in the program. Basically, there are two major classifications
of software, namely System Software and Application Software.
System software: software that is for a computer system. A computer system
consists of many parts so a different type of software is needed for each part.
In other, we can say that system software is for hardware. A user can not
directly interact with system software but without it, he cannot access the
services of particular software. If said in very simple words, then it can be
said that the system software acts as an intermediary between the hardware of
the computer and the user who uses that computer.
For example, if we want to use a printer, then without printer software
(sometimes it is called printer driver software), we cannot use it. With the
help of printer software, the computer performs various functions of the
printer. Sometimes it is also called device drivers. ROM -BIOS driver, printer driver, USB
drivers, motherboard drivers, VGA drivers are some examples of system software.
Sometimes the operating system is also considered as system software.
Application software: Application software is the software that is made for a
particular work. It is written for a particular application. It is also called
end-user software. End-user means that the user interacts with. A computer user
directly interacts with it .every application software is written for a
particular work for example word processor software is made for only word
processing, paintbrush software is made only for painting type of work, the
internet browser is used for browsing the internet, etc.
Ms-office, ms-paint, Tux-paint, notepad, adobe reader, Mozilla Firefox,
Google Chrome, calculator are some very common examples of application
software.
(iii)Human being the most
important element of a computer system is its users.
The user's convenience is seen while designing the interface of any
application software. We cannot imagine the computer world without human
beings. The computer is made by humans and it is made for humans only. Humans
cannot be separated from a computer element. Data analysis, computer
programmer, server administrator, and
computer operators are some important examples of this.
(iv) Data:
data is also a very important element of a computer system. Basically, a
computer is a data processor so without data, a computer cannot perform
anything. Any raw fact is called data and after processing this data becomes
information. Suppose we have to find 799 whether it is an odd or even number,
then we will call 799 as data, and the rule with which we will find out whether
it is even or odd is called a program. And the result that will come out will
be output. So both the result and the program depend on our data, so data is
mandatory for computers. The same data can present many types of results; hence
the demand for data analysis has also increased nowadays. Text, audio, images,
and video are some most common forms of data. With the help of appropriate
software word processing, image processing, audio processing, and video
processing can be performed to get desired output.
(v) Network setup it is not
possible to imagine computers without the internet nowadays. Internet is a
network of networks. it means that the internet is dependent on various kinds
of networks. Most of the networks are belong to the Telecom network for example
BSNL, Airtel,jio, etc. So it is very important for the Internet to have this
kind of network.
Components
of a Computer System
There are basically three main components of a computer
system. Input unit, Process unit, and Output unit. Our computer system is based
on these three main components. If we talk about any element of the computer,
then it will be related to any one of these three components. To understand the
working of the computer, it is very important to understand how these three
components are related, and to understand this; we can take the help of a block
diagram.
Input unit: The main function of this unit is to take data,
commands or instructions. To receive data from the user or any other means
input devices are used. Mouse, keyboard, joystick, scanner, are some most
popular examples of input devices.
Process unit of C.P.U.(central
processing unit ): this is the core unit of a computer system. It is also
called the brain of the computer. Basically, the main task of the computer is
done by this unit. Because of this unit computer is called a data processor. In
a very simple word, we can say that it is not a part of a computer but it is a
computer. The job of this unit is very complicated so it consists of three
parts CPU, memory, and storage.
CPU (central processing unit): it
is a combination of ALU (arithmetic and Logical unit) and CU (control unit).ALU
performs arithmetic operation such as addition; subtraction etc. and CU
perform control operation of the computer system.
Memory: it is a helper of the CPU. As you know we
cannot do anything without memory in the same way CPU also needed memory to
store temporary data in the meanwhile of processing. It is used from taking
data from input devices to show the result. Everywhere temporary memory is
required. To do this RAM (Random Access Memory) is used along with the CPU.
There is also a special type of memory is used that is call ROM (Read Only
Memory).it holds data permanently. It is very costly so only the data that is
required for opening the computer is stored in it. So it can be said that there
are two types of computer memory RAM and ROM. always remember only RAM is
called computer main memory. It is also called primary storage devices.
Difference between RAM and ROM
| Difference | RAM | ROM |
|---|
| Data retention | RAM is a volatile memory that could store the data as long as the power is supplied. | ROM is a non-volatile memory that could retain the data even when power is turned off. |
| Working type | Data stored in RAM can be retrieved and altered. | Data stored in ROM can only be read. |
| Use | Used to store the data that has to be currently processed by CPU temporarily. | It stores the instructions required during bootstrap ( start )of the computer. |
| Speed | It is a high-speed memory. | It is much slower than the RAM. |
| CPU Interaction | The CPU can access the data stored on it. | The CPU can not access the data stored on it unless the data is stored in RAM. |
| Size and Capacity | Large size with higher capacity. | Small size with less capacity. |
| Used as/in | CPU Cache, Primary memory. | Firmware, Micro-controllers |
| Accessibility | The data stored is easily accessible | The data stored is not as easily accessible as in RAM |
| Cost | Costlier | cheaper than RAM. |
Storage: There is some difference between storage and memory.
In general computer, term memory refers to temporary whereas storage means
permanent storage. Mainly secondary storage devices are used for users, not for
computers. This means that secondary storage devices are not used in the data
processing. The main purposes of these devices are to keep user data or system
produced useful information for a long period of time. Examples of these
devices are hard disk, CD, DVD, pen drive, memory card, etc. it is cheaper than
primary storage ROM. generally, it is used to store a huge amount of data. A
normal HDD can store 1/2 terabytes of data.

Output units generally user interact with the input units and
output units. After performing very complex data processing job processor
produce a result but it is in electronic form human being cannot understand it.
So to convert results into human-readable form output devices are used. The
main function of the output unit is to convert digital data into a
human-understandable form. Monitor and printer are the two most common output
devices. Monitor display the result in a soft form on-screen and the printer
produce the result on paper in a hard form so sometimes soft copy and hard copy
terms are used for monitor and printer respectively. Speaker is also an output
device that is used to produce audio for listening.
Computer Generations
We
can divide the generation of computers into five stages. The sequence of
computer generation is as follows.
First Generation (1940-1956)
Vacuum tubes or thermionic
valve machines are used in first-generation computers.
Punched card and the paper
tape were used as an input device.
For output printouts were
used.
ENIAC (Electronic Numerical
Integrator and Computer) was the first electronic computer is introduced in
this generation.
Second Generation (1956-1963)
Transistor technologies were used in this
generation in place of the vacuum tubes.
Second-generation
computers have become much smaller than the first generation.
Computation
speed of second-generation computers was much faster than the first generation so it takes lesser time to produce
results.
Third Generation (1963-1971)
Third
generation of computers is based on Integrated Circuit (IC) technology.
Third
generation computers became much smaller in size than the first and second
generation, and their computation power increased dramatically.
The third
generation computer needs less power and also generated less heat.
The
maintenance cost of the computers in the third generation was also low.
Commercialization
of computers was also started in this generation.
Fourth Generation (1972-2010)
The
invention of microprocessor technology laid the foundation for the fourth
generation computer.
Fourth
generation computers not only became very small in size, but their ability to calculate
also increased greatly and at the same time they became portable, that is, it became very easy to move them from one place to another.
The
computers of fourth-generation started generating a very low amount of heat.
It is
much faster and accuracy became more reliable because of microprocessor technology.
Their
prices have also come down considerably.
Commercialization
of computers has become very fast and it is very easily available for common
people.
Fifth Generation (2010- till date)
AI
(Artificial intelligence) is the backbone technology of this generation of
computers. AI-enabled computers or programs behave like an intelligent person
that’s why this technology is called artificial intelligence technology.
In addition to intelligence, the speed of
computers has also increased significantly and the size has also reduced much
earlier than even the computer on the palm has been used.
Some of
the other popular advanced technologies of the fifth generation include Quantum
computation, Nanotechnology, Parallel processing, Big Data, and IoT, etc.
computer language
A computer cannot understand our language because it is a
machine. So, it understands machine language or we can say that the main
language of computers is machine language. Now the question arises that which
language a machine understands? The answer is very easy; it understands the
language of on and off.
But due to the complexity of the work of computers nowadays,
it is not easy to work with the computer only in the language of on and off, so
some other languages are used for the computer.
Therefore, the language of computers is mainly divided into
three parts.
1. Machine language: - Machine language is the language in which only 0
and 1 two digits are used. Any digital device only understands 0 and 1.It is
the primary language of a computer that the computer understands directly, the
number system which has only two digits is called a binary number system so we
can say that the computer can understand only binary codes. Binary codes have
only two digits 0 and 1 since the computer only understands the binary signal
i.e. 0 and 1 and the computer's circuit i.e. the circuit recognizes these
binary codes and converts it into electrical signals. In this, 0 means Low /off
and 1 means High/ On.
2. Assembly Language: - We use symbols in assembly language because machine
language is difficult for humans, so assembly language was used to make
communication with the computer easier. That is why it is also called symbol
language. Sometimes it is also called low-level language. But one thing must be
understood that the computer understands only and only the language of the
machine. So the computer needs a special type of program, called assembler, to
understand the assembly language. The assembler converts programs written in
assembly language into machine language so that the program written by us can
be understood by the computer. Assembly language is the second generation of
programming language.
3. High-Level
Language: - Symbols were used in assembly language, so it was difficult to
write a program with only symbols, so the need was felt for a language that
uses the alphabet of ordinary English or we can say it that we can understand
and write easily. Writing and understanding high-level language is much easier
than assembly language, so it is quite popular in the computer world with the
help of which it became very easy to write many programs. As the assembler was
used to convert assembly language to machine language, a special type of
software called compiler is used to convert high-level language to machine
language. Some of the major high-level programming languages are C, C ++, JAVA,
HTML, PASCAL, Ruby, etc.
Compiler, Interpreter, Assembler.
A compiler, interpreter, and assembler are three different types of software programs used in the process of programming and software development.
Compiler:
A compiler is a software program that converts the source code written in a high-level programming language into machine code, which can be executed directly by a computer's CPU. It is used to create standalone executable files that can be run on a specific platform. The compiler takes the entire source code as input, performs a series of checks and optimizations, and then generates the executable code.
Interpreter:
An interpreter is a software program that executes the source code line by line. Instead of generating machine code, it translates the source code into an intermediate code, which is then executed by the interpreter. This type of program is often used in scripting languages, where code is interpreted at runtime. An interpreter is slower than a compiler because it needs to read and interpret each line of code each time the program is run.
Assembler:
An assembler is a software program that converts assembly language into machine code. Assembly language is a low-level programming language that uses mnemonic codes to represent instructions that can be executed directly by a computer's CPU. Assemblers are used to create executable files and libraries that can be linked with other code. Unlike compilers and interpreters, assemblers work directly with machine code, making them very efficient but also very difficult to use.
In summary, compilers, interpreters, and assemblers are all used to translate human-readable code into machine-executable code, but they do it in different ways and for different purposes.
ALGORITHM
An algorithm is a finite sequence of well-defined
instructions, typically used to solve a class of specific problems or to
perform a computation.
Characteristics
of an Algorithm
Not all procedures can be called an algorithm.
An algorithm should have the following characteristics −
·
Unambiguous − Algorithm should be clear and
unambiguous. Each of its steps (or phases), and their inputs/outputs should be
clear and must lead to only one meaning.
·
Input − An algorithm should have 0 or more
well-defined inputs.
·
Output − An algorithm should have 1 or more
well-defined outputs, and should match the desired output.
·
Finiteness − Algorithms must terminate after a finite
number of steps.
·
Feasibility − Should be feasible with the available
resources.
·
Independent − An algorithm should have step-by-step
directions, which should be independent of any programming code.
Algorithm example :
Check whether a number is prime or not
Step
1: Start
Step
2: Declare variables n, i, flag.
Step
3: Initialize variables
flag ← 1
i ← 2
Step
4: Read n from the user.
Step
5: Repeat the steps until i=(n/2)
5.1 If remainder of n÷i equals 0
flag ← 0
Go to step 6
5.2 i ← i+1
Step
6: If flag = 0
Display n is not prime
else
Display n is prime
Step
7: Stop
Limitations of algorithm
Limited by the input: An algorithm is limited by the input data it receives. If the input is incorrect or incomplete, the algorithm may not be able to produce the desired output.
Limited by the complexity of the problem: Some problems are so complex that no algorithm can solve them efficiently. This is known as the computational complexity of the problem.
Limited by the computational resources: Algorithms require computational resources such as memory and processing power. If the resources are limited, the algorithm may not be able to solve the problem efficiently.
Limited by the accuracy of the data: Algorithms rely on accurate data to produce correct results. If the data is inaccurate or contains errors, the algorithm may produce incorrect results.
Limited by the assumptions made: Algorithms are often based on assumptions about the data or the problem being solved. If the assumptions are incorrect, the algorithm may produce incorrect results.
Limited by the time constraint: Some problems require a solution within a specific time frame. If the algorithm cannot produce a solution within the time limit, it may not be useful.
Limited by the programmer's ability: The effectiveness of an algorithm is limited by the skill and experience of the programmer who created it. A poorly designed algorithm may not produce the desired results, even if the problem is well-defined.
Flow chart
A flowchart is a
type of diagram that represents a workflow or process. A flowchart can also be defined as a
diagrammatic representation of an algorithm, a step-by-step approach to solving a task.
Example
Pseudo
code:
In computer science, pseudocode is a plain language
description of the steps in an algorithm or another system. Pseudocode often
uses structural conventions of a normal programming language, but is intended
for human reading rather than machine reading. It typically omits details that
are essential for machine understanding of the algorithm, such as variable
declarations and language-specific code.
Flag= 1, i=2
Read n
Repeat until i=(n/2)
If remainder of
n÷i equals 0
flag = 0
i =i+1
end if
end repeat
If flag = 0
Display n
is not prime
else
Display n
is prime
End if
////
Conditions in pseudo code
Pseudo code is a simple language used to express the logic of a computer program algorithm. It is not a real programming language, but it is used to describe the steps in an algorithm using English-like statements. Here are some common conditions used in pseudo code:
IF/THEN: This is used to check a condition and execute a set of instructions if the condition is true.
Example:
IF x > 0 THEN
PRINT "x is positive"
END IF
IF/THEN/ELSE: This is used to check a condition and execute one set of instructions if the condition is true, and another set of instructions if the condition is false.
Example:
IF x > 0 THEN
PRINT "x is positive"
ELSE
PRINT "x is negative or zero"
END IF
WHILE: This is used to execute a set of instructions repeatedly while a condition is true.
Example:
WHILE x > 0 DO
PRINT x
x = x - 1
END WHILE
FOR: This is used to execute a set of instructions a specified number of times.
Example:
FOR i = 1 TO 10 DO
PRINT i
END FOR
SWITCH/CASE: This is used to select one of several sets of instructions to execute based on the value of a variable.
Example:
SWITCH grade
CASE "A"
PRINT "Excellent"
CASE "B"
PRINT "Good"
CASE "C"
PRINT "Fair"
CASE "D"
PRINT "Poor"
CASE ELSE
PRINT "Invalid grade"
END SWITCH
Pseudo code loop
Loops in pseudo code
In pseudo code, loops are used to execute a block of code repeatedly until a certain condition is met. There are different types of loops, such as "for" loops, "while" loops, and "do-while" loops, which can be used depending on the specific use case. Here are some examples of how loops can be expressed in pseudo code:
For loop:
css
Copy code
for i = 1 to 10
// code to be executed
end for
This loop will execute the code inside the loop body 10 times, with the value of i starting at 1 and incrementing by 1 each time through the loop.
While loop:
vbnet
Copy code
while condition
// code to be executed
end while
This loop will execute the code inside the loop body repeatedly as long as the condition is true.
Do-while loop:
javascript
Copy code
do
// code to be executed
while condition
This loop will execute the code inside the loop body at least once, and then repeatedly as long as the condition is true.
Nested loops:
for i = 1 to 10
for j = 1 to 5
// code to be executed
end for
end for
This is an example of a nested loop, where one loop is inside another. In this case, the code inside the inner loop will be executed 5 times for each iteration of the outer loop, resulting in a total of 50 executions of the inner loop code.
UNIT II
----------
What is an Operating System?
An Operating
System (OS) is a software that acts as an interface between computer
hardware components and the user. Every computer system must have at least one
operating system to run other programs. Applications like Browsers, MS Office,
Notepad Games, etc., need some environment to run and perform its tasks.
The
OS helps you to communicate with the computer without knowing how to speak the
computer's language. It is not possible for the user to use any computer or
mobile device without having an operating system.
History Of OS
- Operating systems were first
developed in the late 1950s to manage tape storage
- The General Motors Research Lab
implemented the first OS in the early 1950s for their IBM 701
- In the mid-1960s, operating
systems started to use disks
- In the late 1960s, the first
version of the Unix OS was developed
- The first OS built by Microsoft
was DOS. It was built in 1981 by purchasing the 86-DOS software from a
Seattle company
- The present-day popular OS
Windows first came to existence in 1985 when a GUI was created and paired
with MS-DOS.
Types of Operating System (OS)
Following
are the popular types of Operating System:
- Batch Operating System
- Multitasking/Time Sharing OS
- Multiprocessing OS
- Real Time OS
- Distributed OS
- Network OS
- Mobile OS
Batch Operating System
Some computer processes
are very lengthy and time-consuming. To speed the same process, a job with a
similar type of needs are batched together and run as a group.
The user of a batch
operating system never directly interacts with the computer. In this type of
OS, every user prepares his or her job on an offline device like a punch card
and submit it to the computer operator.
Multi-Tasking/Time-sharing
Operating systems
Time-sharing operating
system enables people located at a different terminal(shell) to use a single
computer system at the same time. The processor time (CPU) which is shared
among multiple users is termed as time sharing.
Real time OS
A real time operating
system time interval to process and respond to inputs is very small. Examples:
Military Software Systems, Space Software Systems are the Real time OS example.
Distributed Operating
System
Distributed systems use
many processors located in different machines to provide very fast computation
to its users.
Network Operating System
Network Operating
System runs on a server. It provides the capability to serve to manage data,
user, groups, security, application, and other networking functions.
Mobile OS
Mobile operating
systems are those OS which is especially that are designed to power
smartphones, tablets, and wearables devices.
Some most famous mobile
operating systems are Android and iOS, but others include BlackBerry, Web, and
watchOS.
Functions of Operating System
Below
are the main functions of Operating System:
- Process management:- Process management helps OS to create and delete
processes. It also provides mechanisms for synchronization and
communication among processes.
- Memory management:- Memory management module performs the task of
allocation and de-allocation of memory space to programs in need of this
resources.
- File management:- It manages all the file-related activities such as
organization storage, retrieval, naming, sharing, and protection of files.
- Device Management: Device management keeps tracks of all devices. This
module also responsible for this task is known as the I/O controller. It
also performs the task of allocation and de-allocation of the devices.
- I/O System Management: One of the main objects of any OS is to hide the
peculiarities of that hardware devices from the user.
- Secondary-Storage Management: Systems have several levels of storage which includes
primary storage, secondary storage, and cache storage. Instructions and
data must be stored in primary storage or cache so that a running program
can reference it.
- Security:- Security module protects the data and information of
a computer system against malware threat and authorized access.
- Command interpretation: This module is interpreting commands given by the and
acting system resources to process that commands.
- Networking: A distributed system is a group of processors
which do not share memory, hardware devices, or a clock. The processors
communicate with one another through the network.
- Job accounting: Keeping track of time & resource used by various
job and users.
- Communication management: Coordination and assignment of compilers,
interpreters, and another software resource of the various users of the
computer systems.
Features of Operating System (OS)
Here
is a list important features of OS:
- Protected and supervisor mode
- Allows disk access and file
systems Device drivers Networking Security
- Program Execution
- Memory management Virtual
Memory Multitasking
- Handling I/O operations
- Manipulation of the file system
- Error Detection and handling
- Resource allocation
- Information and Resource
Protection
////
Elements of command based and GUI based operating system
Command-based operating systems (CLI):
Command Line Interface (CLI): Command-based operating systems use a command line interface, which is a text-based interface that allows users to enter commands to perform tasks.
Shell: The shell is a program that provides the interface between the user and the operating system. It interprets the commands entered by the user and executes them.
Command interpreter: The command interpreter is a program that interprets the commands entered by the user and converts them into machine language that the computer can understand.
Command prompt: The command prompt is a text-based prompt that indicates that the operating system is ready to accept commands from the user.
GUI-based operating systems:
Graphical User Interface (GUI): GUI-based operating systems use a graphical user interface, which is a visual interface that allows users to interact with the operating system using graphical elements such as icons, windows, and menus.
Desktop: The desktop is the graphical interface that is displayed when the user logs into the operating system. It provides a visual representation of the computer's file system and allows users to launch applications and access files.
Window Manager: The window manager is a program that manages the display of windows on the desktop. It allows users to move and resize windows and switch between different applications.
Icons: Icons are graphical representations of applications or files that allow users to launch applications and access files by clicking on them.
Menus: Menus are graphical elements that allow users to access various functions of the operating system and applications by selecting them from a list of options.
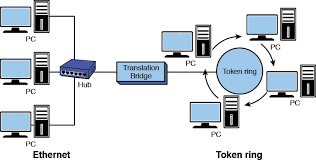
Computer Network
A computer network is a group of computers linked to each other that
enables the computer to communicate with another computer and share their
resources, data, and applications.
A computer network can be categorized by their size. A computer
network is mainly of four types:
- LAN(Local
Area Network)
- MAN(Metropolitan
Area Network)
- WAN(Wide
Area Network)
LAN(Local Area Network)
- Local
Area Network is a group of computers connected to each other in a small
area such as building, office.
- LAN is
used for connecting two or more personal computers through a communication
medium such as twisted pair, coaxial cable, etc.
- It is
less costly as it is built with inexpensive hardware such as hubs, network
adapters, and ethernet cables.
- The data
is transferred at an extremely faster rate in Local Area Network.
- Local
Area Network provides higher security.
MAN(Metropolitan Area
Network)
- A
metropolitan area network is a network that covers a larger geographic
area by interconnecting a different LAN to form a larger network.
- Government
agencies use MAN to connect to the citizens and private industries.
- In MAN,
various LANs are connected to each other through a telephone exchange
line.
- The most
widely used protocols in MAN are RS-232, Frame Relay, ATM, ISDN, OC-3,
ADSL, etc.
- It has a
higher range than Local Area Network(LAN).
Uses Of Metropolitan
Area Network:
- MAN is
used in communication between the banks in a city.
- It can be
used in an Airline Reservation.
- It can be
used in a college within a city.
- It can
also be used for communication in the military.
WAN(Wide Area Network)
- A Wide
Area Network is a network that extends over a large geographical area such
as states or countries.
- A Wide
Area Network is quite bigger network than the LAN.
- A Wide
Area Network is not limited to a single location, but it spans over a
large geographical area through a telephone line, fibre optic cable or
satellite links.
- The
internet is one of the biggest WAN in the world.
- A Wide
Area Network is widely used in the field of Business, government, and
education.
Examples Of Wide Area
Network:
- Mobile Broadband: A 4G network is widely used across a
region or country.
- Last mile: A telecom company is used to provide the
internet services to the customers in hundreds of cities by connecting
their home with fiber.
- Private network: A bank provides a private network that
connects the 44 offices. This network is made by using the telephone
leased line provided by the telecom company.
Advantages Of Wide Area
Network:
Following are the advantages of the Wide Area Network:
- Geographical area: A Wide Area Network provides a large
geographical area. Suppose if the branch of our office is in a different
city then we can connect with them through WAN. The internet provides a
leased line through which we can connect with another branch.
- Centralized data: In case of WAN network, data is
centralized. Therefore, we do not need to buy the emails, files or back up
servers.
- Get updated files: Software companies work on the live
server. Therefore, the programmers get the updated files within seconds.
- Exchange messages: In a WAN network, messages are
transmitted fast. The web application like Facebook, Whatsapp, Skype
allows you to communicate with friends.
- Sharing of software and resources: In WAN network, we can share the software
and other resources like a hard drive, RAM.
- Global business: We can do the business over the internet
globally.
- High bandwidth: If we use the leased lines for our
company then this gives the high bandwidth. The high bandwidth increases
the data transfer rate which in turn increases the productivity of our
company.
Disadvantages of Wide
Area Network:
The following are the disadvantages of the Wide Area Network:
- Security issue: A WAN network has more security issues as
compared to LAN and MAN network as all the technologies are combined
together that creates the security problem.
- Needs Firewall & antivirus
software: The
data is transferred on the internet which can be changed or hacked by the
hackers, so the firewall needs to be used. Some people can inject the
virus in our system so antivirus is needed to protect from such a virus.
- High Setup cost: An installation cost of the WAN network
is high as it involves the purchasing of routers, switches.
- Troubleshooting problems: It covers a large area so fixing the
problem is difficult.
Internetwork
- An
internetwork is defined as two or more computer network LANs or WAN or
computer network segments are connected using devices, and they are
configured by a local addressing scheme. This process is known as internetworking.
- An
interconnection between public, private, commercial, industrial, or
government computer networks can also be defined as internetworking.
- An
internetworking uses the internet protocol.
- The
reference model used for internetworking is Open System
Interconnection(OSI).
Types of Internetwork:
1. Extranet: An extranet is a communication network
based on the internet protocol such as Transmission Control protocol and internet
protocol. It is used for information sharing. The access to the extranet is
restricted to only those users who have login credentials. An extranet is the
lowest level of internetworking. It can be categorized as MAN, WAN or
other computer networks. An extranet cannot have a single LAN,
atleast it must have one connection to the external network.
2. Intranet: An intranet is a private network based on
the internet protocol such as Transmission Control protocol and internet
protocol. An intranet belongs to an organization which is only accessible
by the organization's employee or members. The main aim of the
intranet is to share the information and resources among the organization
employees. An intranet provides the facility to work in groups and for
teleconferences.
Intranet advantages:
- Communication: It provides a cheap and easy
communication. An employee of the organization can communicate with
another employee through email, chat.
- Time-saving: Information on the intranet is shared in
real time, so it is time-saving.
- Collaboration: Collaboration is one of the most
important advantage of the intranet. The information is distributed among
the employees of the organization and can only be accessed by the
authorized user.
- Platform independency: It is a neutral architecture as the
computer can be connected to another device with different architecture.
- Cost effective: People can see the data and documents by
using the browser and distributes the duplicate copies over the intranet.
This leads to a reduction in the cost.
Primary
Network Topologies
The way in which devices are interconnected to form a network is
called network topology. Some of the factors that affect choice of topology for
a network are −
- Cost−
Installation cost is a very important factor in overall cost of setting up
an infrastructure. So cable lengths, distance between nodes, location of
servers, etc. have to be considered when designing a network.
- Flexibility−
Topology of a network should be flexible enough to allow reconfiguration
of office set up, addition of new nodes and relocation of existing nodes.
- Reliability−
Network should be designed in such a way that it has minimum down time.
Failure of one node or a segment of cabling should not render the whole
network useless.
- Scalability−
Network topology should be scalable, i.e. it can accommodate load of new
devices and nodes without perceptible drop in performance.
- Ease of
installation− Network should be easy to install in terms of hardware,
software and technical personnel requirements.
- Ease of
maintenance− Troubleshooting and maintenance of network should be easy.
Topology defines the structure of
the network of how all the components are interconnected to each other. There
are two types of topology: physical and logical topology.
Physical topology is the geometric representation of all the nodes in a
network.
Bus Topology
- The bus
topology is designed in such a way that all the stations are connected
through a single cable known as a backbone cable.
- Each node
is either connected to the backbone cable by drop cable or directly
connected to the backbone cable.
- When a
node wants to send a message over the network, it puts a message over the
network. All the stations available in the network will receive the message
whether it has been addressed or not.
- The bus
topology is mainly used in 802.3 (ethernet) and 802.4 standard networks.
- The
configuration of a bus topology is quite simpler as compared to other
topologies.
- The
backbone cable is considered as a "single lane" through
which the message is broadcast to all the stations.
- The most
common access method of the bus topologies is CSMA (Carrier
Sense Multiple Access).
CSMA: It is a media access control used to control
the data flow so that data integrity is maintained, i.e., the packets do not
get lost. There are two alternative ways of handling the problems that occur
when two nodes send the messages simultaneously.
- CSMA CD: CSMA CD (Collision detection) is
an access method used to detect the collision. Once the collision is
detected, the sender will stop transmitting the data. Therefore, it works
on "recovery after the collision".
- CSMA CA: CSMA CA (Collision Avoidance) is
an access method used to avoid the collision by checking whether the
transmission media is busy or not. If busy, then the sender waits until
the media becomes idle. This technique effectively reduces the possibility
of the collision. It does not work on "recovery after the
collision".
Advantages of Bus
topology:
- Low-cost cable: In bus topology, nodes are directly
connected to the cable without passing through a hub. Therefore, the
initial cost of installation is low.
- Moderate data speeds: Coaxial or twisted pair cables are mainly
used in bus-based networks that support upto 10 Mbps.
- Familiar technology: Bus topology is a familiar technology as
the installation and troubleshooting techniques are well known, and
hardware components are easily available.
- Limited failure: A failure in one node will not have any
effect on other nodes.
Disadvantages of Bus
topology:
- Extensive cabling: A bus topology is quite simpler, but
still it requires a lot of cabling.
- Difficult troubleshooting: It requires specialized test equipment to
determine the cable faults. If any fault occurs in the cable, then it
would disrupt the communication for all the nodes.
- Signal interference: If two nodes send the messages
simultaneously, then the signals of both the nodes collide with each
other.
- Reconfiguration difficult: Adding new devices to the network would
slow down the network.
- Attenuation: Attenuation is a loss of signal leads to
communication issues. Repeaters are used to regenerate the signal.
Ring Topology
- Ring
topology is like a bus topology, but with connected ends.
- The node
that receives the message from the previous computer will re-transmit to
the next node.
- The data
flows in one direction, i.e., it is unidirectional.
- The data
flows in a single loop continuously known as an endless loop.
- It has no
terminated ends, i.e., each node is connected to another node and has no
termination point.
- The data
in a ring topology flow in a clockwise direction.
- The most
common access method of the ring topology is token passing.
- Token passing: It is a network access method in which
token is passed from one node to another node.
- Token: It is a frame that circulates around the
network.
Working of Token
passing
- A token
moves around the network, and it is passed from computer to computer until
it reaches the destination.
- The
sender modifies the token by putting the address along with the data.
- The data
is passed from one device to another device until the destination address
matches. Once the token received by the destination device, then it sends
the acknowledgment to the sender.
- In a ring
topology, a token is used as a carrier.
Advantages of Ring
topology:
- Network Management: Faulty devices can be removed from the
network without bringing the network down.
- Product availability: Many hardware and software tools for
network operation and monitoring are available.
- Cost: Twisted pair cabling is inexpensive and
easily available. Therefore, the installation cost is very low.
- Reliable: It is a more reliable network because the
communication system is not dependent on the single host computer.
Disadvantages of Ring
topology:
- Difficult troubleshooting: It requires specialized test equipment to
determine the cable faults. If any fault occurs in the cable, then it
would disrupt the communication for all the nodes.
- Failure: The breakdown in one station leads to the
failure of the overall network.
- Reconfiguration difficult: Adding new devices to the network would
slow down the network.
- Delay: Communication delay is directly
proportional to the number of nodes. Adding new devices increases the
communication delay.
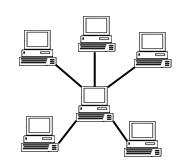
Star Topology
- Star
topology is an arrangement of the network in which every node is connected
to the central hub, switch or a central computer.
- The
central computer is known as a server, and the peripheral
devices attached to the server are known as clients.
- Coaxial
cable or RJ-45 cables are used to connect the computers.
- Hubs or
Switches are mainly used as connection devices in a physical star
topology.
- Star
topology is the most popular topology in network implementation.
Advantages of Star
topology
- Efficient troubleshooting: Troubleshooting is quite efficient in a
star topology as compared to bus topology. In a bus topology, the manager
has to inspect the kilometers of cable. In a star topology, all the
stations are connected to the centralized network. Therefore, the network
administrator has to go to the single station to troubleshoot the problem.
- Network control: Complex network control features can be
easily implemented in the star topology. Any changes made in the star
topology are automatically accommodated.
- Limited failure: As each station is connected to the
central hub with its own cable, therefore failure in one cable will not
affect the entire network.
- Familiar technology: Star topology is a familiar technology as
its tools are cost-effective.
- Easily expandable: It is easily expandable as new stations
can be added to the open ports on the hub.
- Cost effective: Star topology networks are cost-effective
as it uses inexpensive coaxial cable.
- High data speeds: It supports a bandwidth of approx
100Mbps. Ethernet 100BaseT is one of the most popular Star topology
networks.
Disadvantages of Star
topology
- A Central point of failure: If the central hub or switch goes down,
then all the connected nodes will not be able to communicate with each
other.
- Cable: Sometimes cable routing becomes difficult
when a significant amount of routing is required.
Tree topology
- Tree
topology combines the characteristics of bus topology and star topology.
- A tree
topology is a type of structure in which all the computers are connected
with each other in hierarchical fashion.
- The
top-most node in tree topology is known as a root node, and all other
nodes are the descendants of the root node.
- There is
only one path exists between two nodes for the data transmission. Thus, it
forms a parent-child hierarchy.
Advantages of Tree
topology
- Support for broadband transmission: Tree topology is mainly used to provide
broadband transmission, i.e., signals are sent over long distances without
being attenuated.
- Easily expandable: We can add the new device to the existing
network. Therefore, we can say that tree topology is easily expandable.
- Easily manageable: In tree topology, the whole network is
divided into segments known as star networks which can be easily managed
and maintained.
- Error detection: Error detection and error correction are
very easy in a tree topology.
- Limited failure: The breakdown in one station does not
affect the entire network.
- Point-to-point wiring: It has point-to-point wiring for
individual segments.
Disadvantages of Tree
topology
- Difficult troubleshooting: If any fault occurs in the node, then it
becomes difficult to troubleshoot the problem.
- High cost: Devices required for broadband
transmission are very costly.
- Failure: A tree topology mainly relies on main bus
cable and failure in main bus cable will damage the overall network.
- Reconfiguration difficult: If new devices are added, then it becomes
difficult to reconfigure.
Mesh topology
- Mesh
technology is an arrangement of the network in which computers are
interconnected with each other through various redundant connections.
- There are
multiple paths from one computer to another computer.
- It does
not contain the switch, hub or any central computer which acts as a
central point of communication.
- The
Internet is an example of the mesh topology.
- Mesh
topology is mainly used for WAN implementations where communication
failures are a critical concern.
- Mesh
topology is mainly used for wireless networks.
Mesh topology is
divided into two categories:
- Fully
connected mesh topology
- Partially
connected mesh topology
- Full Mesh Topology: In a full mesh topology, each computer is
connected to all the computers available in the network.
- Partial Mesh Topology: In a partial mesh topology, not all but
certain computers are connected to those computers with which they
communicate frequently.
Advantages of Mesh topology:
Reliable: The mesh topology networks are very reliable
as if any link breakdown will not affect the communication between connected
computers.
Fast Communication: Communication is very fast between the nodes.
Easier Reconfiguration: Adding new devices would not disrupt the
communication between other devices.
Disadvantages of Mesh
topology
- Cost: A mesh topology contains a large number
of connected devices such as a router and more transmission media than
other topologies.
- Management: Mesh topology networks are very large and
very difficult to maintain and manage. If the network is not monitored
carefully, then the communication link failure goes undetected.
- Efficiency: In this topology, redundant connections
are high that reduces the efficiency of the network.
What are network devices?
Network devices, or networking hardware, are physical devices that are required for communication and interaction between hardware on a computer network.
Types of network devices
Here is the common network device list:
Hub
Hubs connect multiple
computer networking devices together. A hub also acts as a repeater in that it
amplifies signals that deteriorate after traveling long distances over
connecting cables. A hub is the simplest in the family of network connecting
devices because it connects LAN components with identical protocols.
A hub can be used with
both digital and analog data, provided its settings have been configured to
prepare for the formatting of the incoming data. For example, if the incoming
data is in digital format, the hub must pass it on as packets; however, if the
incoming data is analog, then the hub passes it on in signal form.
Hubs do not perform
packet filtering or addressing functions; they just send data packets to all
connected devices. Hubs operate at the Physical layer of the Open Systems Interconnection (OSI) model.
There are two types of hubs: simple and multiple port.
Switch
Switches generally
have a more intelligent role than hubs. A switch is a multiport device that
improves network efficiency. The switch maintains limited routing information
about nodes in the internal network, and it allows connections to systems like
hubs or routers. Strands of LANs are usually connected using switches.
Generally, switches can read the hardware addresses of incoming packets to
transmit them to the appropriate destination.
Using switches
improves network efficiency over hubs or routers because of the virtual circuit
capability. Switches also improve network security because the virtual circuits
are more difficult to examine with network monitors. You can think of a switch
as a device that has some of the best capabilities of routers and hubs
combined. A switch can work at either the Data Link layer or the Network layer
of the OSI model. A multilayer switch is one that can operate at both layers,
which means that it can operate as both a switch and a router. A multilayer
switch is a high-performance device that supports the same routing protocols as
routers.
Switches can be
subject to distributed denial of service (DDoS) attacks; flood guards are used
to prevent malicious traffic from bringing the switch to a halt. Switch port
security is important so be sure to secure switches: Disable all unused ports
and use DHCP snooping, ARP inspection and MAC address filtering.
Router
Routers help transmit
packets to their destinations by charting a path through the sea of
interconnected networking devices using different network topologies. Routers
are intelligent devices, and they store information about the networks they’re
connected to. Most routers can be configured to operate as packet-filtering
firewalls and use access control lists (ACLs). Routers, in conjunction with a
channel service unit/data service unit (CSU/DSU), are also used to translate
from LAN framing to WAN framing. This is needed because LANs and WANs use
different network protocols. Such routers are known as border routers. They
serve as the outside connection of a LAN to a WAN, and they operate at the border
of your network.
Router are also used
to divide internal networks into two or more subnetworks. Routers can also be
connected internally to other routers, creating zones that operate
independently. Routers establish communication by maintaining tables about
destinations and local connections. A router contains information about the
systems connected to it and where to send requests if the destination isn’t
known. Routers usually communicate routing and other information using one of
three standard protocols: Routing Information Protocol (RIP), Border Gateway
Protocol (BGP) or Open Shortest Path First (OSPF).
Routers are your first
line of defense, and they must be configured to pass only traffic that is
authorized by network administrators. The routes themselves can be configured
as static or dynamic. If they are static, they can only be configured manually
and stay that way until changed. If they are dynamic, they learn of other
routers around them and use information about those routers to build their routing
tables.
Routers are
general-purpose devices that interconnect two or more heterogeneous networks.
They are usually dedicated to special-purpose computers, with separate input
and output network interfaces for each connected network. Because routers and
gateways are the backbone of large computer networks like the internet, they
have special features that give them the flexibility and the ability to cope
with varying network addressing schemes and frame sizes through segmentation of
big packets into smaller sizes that fit the new network components. Each router
interface has its own Address Resolution Protocol (ARP) module, its own LAN
address (network card address) and its own Internet Protocol (IP) address. The
router, with the help of a routing table, has knowledge of routes a packet
could take from its source to its destination. The routing table, like in the
bridge and switch, grows dynamically. Upon receipt of a packet, the router
removes the packet headers and trailers and analyzes the IP header by determining
the source and destination addresses and data type, and noting the arrival
time. It also updates the router table with new addresses not already in the
table. The IP header and arrival time information is entered in the routing
table. Routers normally work at the Network layer of the OSI model.
Bridge
Bridges are used to
connect two or more hosts or network segments together. The basic role of
bridges in network architecture is storing and forwarding frames between the
different segments that the bridge connects. They use hardware Media Access
Control (MAC) addresses for transferring frames. By looking at the MAC address
of the devices connected to each segment, bridges can forward the data or block
it from crossing. Bridges can also be used to connect two physical LANs into a
larger logical LAN.
Bridges work only at
the Physical and Data Link layers of the OSI model. Bridges are used to divide
larger networks into smaller sections by sitting between two physical network
segments and managing the flow of data between the two.
Bridges are like hubs
in many respects, including the fact that they connect LAN components with
identical protocols. However, bridges filter incoming data packets, known as
frames, for addresses before they are forwarded. As it filters the data
packets, the bridge makes no modifications to the format or content of the
incoming data. The bridge filters and forwards frames on the network with the
help of a dynamic bridge table. The bridge table, which is initially empty,
maintains the LAN addresses for each computer in the LAN and the addresses of
each bridge interface that connects the LAN to other LANs. Bridges, like hubs,
can be either simple or multiple port.
Bridges have mostly
fallen out of favor in recent years and have been replaced by switches, which
offer more functionality. In fact, switches are sometimes referred to as
“multiport bridges” because of how they operate.
Gateway
Gateways normally work
at the Transport and Session layers of the OSI model. At the Transport layer
and above, there are numerous protocols and standards from different vendors;
gateways are used to deal with them. Gateways provide translation between
networking technologies such as Open System Interconnection (OSI) and
Transmission Control Protocol/Internet Protocol (TCP/IP). Because of this,
gateways connect two or more autonomous networks, each with its own routing
algorithms, protocols, topology, domain name service, and network
administration procedures and policies.
Gateways perform all
of the functions of routers and more. In fact, a router with added translation
functionality is a gateway. The function that does the translation between
different network technologies is called a protocol converter.
Modem
Modems
(modulators-demodulators) are used to transmit digital signals over analog
telephone lines. Thus, digital signals are converted by the modem into analog
signals of different frequencies and transmitted to a modem at the receiving
location. The receiving modem performs the reverse transformation and provides
a digital output to a device connected to a modem, usually a computer. The
digital data is usually transferred to or from the modem over a serial line
through an industry standard interface, RS-232. Many telephone companies offer
DSL services, and many cable operators use modems as end terminals for
identification and recognition of home and personal users. Modems work on both
the Physical and Data Link layers.
Repeater
A repeater is an
electronic device that amplifies the signal it receives. You can think of repeater
as a device which receives a signal and retransmits it at a higher level or
higher power so that the signal can cover longer distances, more than 100
meters for standard LAN cables. Repeaters work on the Physical layer.
Access Point
While an access point
(AP) can technically involve either a wired or wireless connection, it commonly
means a wireless device. An AP works at the second OSI layer, the Data Link
layer, and it can operate either as a bridge connecting a standard wired
network to wireless devices or as a router passing data transmissions from one
access point to another.
Wireless access points
(WAPs) consist of a transmitter and receiver (transceiver) device used to
create a wireless LAN (WLAN). Access points typically are separate network devices
with a built-in antenna, transmitter and adapter. APs use the wireless
infrastructure network mode to provide a connection point between WLANs and a
wired Ethernet LAN. They also have several ports, giving you a way to expand
the network to support additional clients. Depending on the size of the
network, one or more APs might be required to provide full coverage. Additional
APs are used to allow access to more wireless clients and to expand the range
of the wireless network. Each AP is limited by its transmission range — the
distance a client can be from an AP and still obtain a usable signal and data
process speed. The actual distance depends on the wireless standard, the
obstructions and environmental conditions between the client and the AP. Higher
end APs have high-powered antennas, enabling them to extend how far the
wireless signal can travel.
APs might also provide
many ports that can be used to increase the network’s size, firewall
capabilities and Dynamic Host Configuration Protocol (DHCP) service. Therefore,
we get APs that are a switch, DHCP server, router and firewall.
To connect to a
wireless AP, you need a service set identifier (SSID) name. 802.11 wireless
networks use the SSID to identify all systems belonging to the same network,
and client stations must be configured with the SSID to be authenticated to the
AP. The AP might broadcast the SSID, allowing all wireless clients in the area
to see the AP’s SSID. However, for security reasons, APs can be configured not
to broadcast the SSID, which means that an administrator needs to give client
systems the SSID instead of allowing it to be discovered automatically.
Wireless devices ship with default SSIDs, security settings, channels,
passwords and usernames. For security reasons, it is strongly recommended that
you change these default settings as soon as possible because many internet
sites list the default settings used by manufacturers.
Access points can be
fat or thin. Fat APs, sometimes still referred to as autonomous APs, need to be
manually configured with network and security settings; then they are
essentially left alone to serve clients until they can no longer function. Thin
APs allow remote configuration using a controller. Since thin clients do not
need to be manually configured, they can be easily reconfigured and monitored.
Access points can also be controller-based or stand-alone.
UNIT III
----------
The Internet is the global system of interconnected
computer networks that uses the Internet protocol suite (TCP/IP) to communicate
between networks and devices. It is a network of networks that consists of
private, public, academic, business, and government networks of local to global
scope, linked by a broad array of electronic, wireless, and optical networking
technologies. The Internet carries a vast range of information resources and
services, such as the inter-linked hypertext documents and applications of the
World Wide Web (WWW), electronic mail, telephony, and file sharing.

Internet architecture
Functioning of internet
The internet is a global network of connected computers and servers that allows users to access and share information and resources from anywhere in the world. The basic functioning of the internet involves several interconnected layers of hardware and software that work together to transmit data between devices.
Here is a simplified overview of how the internet works:
Devices: The internet is accessed through various devices such as computers, smartphones, tablets, and servers that are connected to the network.
Protocols: The internet uses a set of standardized protocols, including TCP/IP (Transmission Control Protocol/Internet Protocol), to transmit and receive data packets between devices.
ISP: Internet Service Providers (ISPs) provide users with access to the internet by connecting their devices to the network via wired or wireless connections.
DNS: Domain Name System (DNS) servers translate human-readable domain names (such as www.google.com) into IP addresses (such as 172.217.5.78) that computers can understand.
Routing: When a user sends data over the internet, it is broken up into small packets and sent through a series of routers that determine the best path for the data to take to reach its destination.
Websites and servers: Websites and other online services are hosted on servers that are connected to the internet and provide users with access to content and resources.
Encryption: To ensure the security and privacy of data transmitted over the internet, encryption protocols such as SSL (Secure Sockets Layer) and TLS (Transport Layer Security) are used to encrypt data before it is transmitted and decrypt it when it is received.
Overall, the internet is a complex and constantly evolving network that requires the cooperation of many different devices and technologies to function effectively.
WWW
The World Wide Web
(WWW) is a network of online content that is formatted in HTML and accessed via
HTTP. The term refers to all the interlinked HTML pages that can be accessed
over the Internet. The World Wide Web was originally designed in 1991 by Tim
Berners-Lee while he was a contractor at CERN.
The World Wide Web is
most often referred to simply as “the Web.”
The World Wide Web is
what most people think of as the Internet. It is all the Web pages, pictures,
videos and other online content that can be accessed via a Web browser. The
Internet, in contrast, is the underlying network connection that allows us to
send email and access the World Wide Web. The early Web was a collection of
text-based sites hosted by organizations that were technically gifted enough to
set up a Web server and learn HTML. It has continued to evolve since the
original design, and it now includes interactive (social) media and user-generated
content that requires little to no technical skills.
We owe the free Web to
Berners-Lee and CERN’s decision to give away one of the greatest inventions of
the century.
FTP
File Transfer Protocol
(FTP) is a standard Internet protocol for transmitting files between computers
on the Internet over TCP/IP connections. FTP is a client-server protocol where
a client will ask for a file, and a local or remote server will provide it.
The end-users machine
is typically called the local host machine, which is connected via the internet
to the remote host—which is the second machine running the FTP software.
Anonymous FTP is a type
of FTP that allows users to access files and other data without needing an ID
or password. Some websites will allow visitors to use a guest ID or password-
anonymous FTP allows this.
Although a lot of file
transfer is now handled using HTTP, FTP is still commonly used to transfer
files “behind the scenes” for other applications — e.g., hidden behind the user
interfaces of banking, a service that helps build a website, such as Wix or
SquareSpace, or other services. It is also used, via Web browsers, to download
new applications.
How
FTP works
FTP is a client-server
protocol that relies on two communications channels between client and server:
a command channel for controlling the conversation and a data channel for
transmitting file content. Clients initiate conversations with servers by
requesting to download a file. Using FTP, a client can upload, download,
delete, rename, move and copy files on a server. A user typically needs to log
on to the FTP server, although some servers make some or all of their content
available without login, known as anonymous FTP.
FTP sessions work in
passive or active modes. In active mode, after a client initiates a session via
a command channel request, the server initiates a data connection back to the
client and begins transferring data. In passive mode, the server instead uses
the command channel to send the client the information it needs to open a data
channel. Because passive mode has the client initiating all connections, it
works well across firewalls and Network Address Translation (NAT) gateways.
How to FTP
Files can be
transferred between two computers using FTP software. The user’s computer is
called the local host machine and is connected to the Internet. The second
machine, called the remote host, is also running FTP software and connected to
the Internet.
- The local host machine connects to
the remote host’s IP address.
- The user would enter a
username/password (or use anonymous).
- FTP software may have a GUI,
allowing users to drag and drop files between the remote and local host.
If not, a series of FTP commandsare used to log in to the remote host
and transfer files between the machines
Telnet
Telnet is a network protocol used to establish a remote terminal session with another computer or device over a network. It is a client-server protocol where the Telnet client software runs on the local computer, and the Telnet server software runs on the remote device.
The Telnet protocol was first developed in 1969 and is still used today, although it has largely been replaced by more secure protocols like SSH (Secure Shell).
Telnet uses TCP (Transmission Control Protocol) as its underlying transport protocol and typically runs on port 23. Once a Telnet session is established, the user can enter commands and interact with the remote device as if they were physically sitting in front of it.
One of the key advantages of Telnet is that it enables remote access to devices without the need for specialized hardware or software. However, because Telnet sends all data, including login credentials, in plain text, it is not a secure protocol and is susceptible to eavesdropping and man-in-the-middle attacks.
To address these security concerns, many organizations have switched to more secure protocols like SSH or VPNs (Virtual Private Networks).
Web Browsers
A web browser is a software
program that allows a user to locate, access, and display web pages. In common
usage, a web browser is usually shortened to “browser.” Browsers are used
primarily for displaying and accessing websites on the internet, as well as
other content created using languages such as Hypertext Markup Language (HTML)
and Extensible Markup Language (XML).
Browsers translate web pages
and websites delivered using Hypertext Transfer Protocol (HTTP) into
human-readable content. They also have the ability to display other protocols
and prefixes, such as secure HTTP (HTTPS), File Transfer Protocol (FTP), email
handling (mailto:), and files (file:). In addition, most browsers also support
external plug-ins required to display active content, such as in-page video,
audio and game content.
A variety of web browsers are
available with different features, and are designed to run on different
operating systems. Common browsers include Internet Explorer from Microsoft,
Firefox from Mozilla, Google Chrome, Safari from Apple, and Opera. All major
browsers have mobile versions that are lightweight versions for accessing the
web on mobile devices.
Web browsers date back to the
late 1980s when an English scientist, Tim Berners-Lee, first developed the
ideas that led to the World Wide Web (WWW). This consisted of a series of pages
created using the HTML language and joined or linked together with pointers
called hyperlinks. Following this was the need for a program that could access
and display the HTML pages correctly – the browser.
In 1993, a new browser known as Mosaic was
developed, which soon gained widespread usage due to its graphical-interface
capability. Marc Andreesen, a member of the Mosaic development team, left in
1994 to develop his own commercial browser based on Mosaic. He called it
Netscape Navigator and it quickly captured over 90 percent of the nascent
browser market. It soon faced stiff competition in 1995 from Microsoft’s
Internet Explorer, which was freely bundled with Windows 95 (and later versions
of Windows). It was pointless to buy Navigator when Internet Explorer was free,
and as a result, Navigator (and Netscape) were driven into the ground. But
while Mosaic and Netscape are no longer around, the age of the browser was
launched and continues to this day, as more and more applications move to the
web.
Search Engines
Search engine is a service that allows Internet users
to search for content via the World Wide Web (WWW). A user enters keywords or
key phrases into a search engine and receives a list of Web content results in
the form of websites, images, videos or other online data. The list of content
returned via a search engine to a user is known as a search engine results page
(SERP).
To simplify, think of a search engine as two
components. First a spider/web crawler trolls the web for content that is added
to the search engine’s index. Then, when a user queries a search engine,
relevant results are returned based on the search engine’s algorithm. Early
search engines were based largely on page content, but as websites learned to
game the system, algorithms have become much more complex and search results
returned can be based on literally hundreds of variables.
There used to be a significant number of search engines
with significant market share. Currently, Google and Microsoft’s Bing control
the vast majority of the market. (While Yahoo generates many queries, their
back-end search technology is outsourced to Microsoft.)
E-Mail
E-mail (electronic mail) is the exchange of
computer-stored messages by telecommunication. (Some publications spell it
email; we prefer the currently more established spelling of e-mail.) E-mail
messages are usually encoded in ASCII text. However, you can also send non-text
files, such as graphic images and sound files, as attachments sent in binary
streams. E-mail was one of the first uses of the Internet and is still the most
popular use. A large percentage of the total traffic over the Internet is
e-mail. E-mail can also be exchanged between online service provider users and
in networks other than the Internet, both public and private.
E-mail can be distributed to lists of people as well as
to individuals. A shared distribution list can be managed by using an e-mail
reflector. Some mailing lists allow you to subscribe by sending a request to
the mailing list administrator. A mailing list that is administered
automatically is called a list server.
E-mail is one of the protocols included with the
Transport Control Protocol/Internet Protocol (TCP/IP) suite of protocols. A
popular protocol for sending e-mail is Simple Mail Transfer Protocol and a
popular protocol for receiving it is POP3. Both Netscape and Microsoft include
an e-mail utility with their Web browsers.
Gopher
Gopher
is a client/server directory system that launched in 1991. It
allowed people to quickly browse resources on the internet. When you used a
Gopher client, you would see a hierarchical menu of links that either led to
documents, telnet-based applications, FTP sites, or other Gopher servers.
The Gopher is a communication protocol designed
for distributing, searching, and retrieving documents in Internet Protocol
networks. The design of the Gopher protocol and user interface is menu-.driven,
and presented an alternative to the World Wide Web .
Gopher
is an Internet application that allows you to browse many different kinds of
resources by looking at menus or listings of information available. Its
function is easy to remember because of its name: you use Gopher to "go
fer" information that is on other computers all over the world. The menus
in the Gopher system allow you to see what information is there; the Gopher
client on your system then brings the information you want to your computer
screen. The Gopher servers of the world are all interconnected and have been
compared to a large library full of resources.
You
need to have a Gopher client running on your server to access and use this
application. To find out if you have Gopher, either click on the Gopher icon or
type "Gopher" at the command prompt. If your system is running a
Gopher client, this will connect you to a root menu of resources from which you
can proceed to browse the "libraries" of the world. The menus are
constructed in a hierarchical order; to return from whence you came you simply
need to type "u" for "up"--this takes you up to the next
menu level. You can also just "quit" the application from whatever
point you are. Some Gophers are text-based and others use icons (graphical
representations) to lead from menu to menu.
If
you find a site with interesting and useful information, you can mark it by
using the bookmark function of the Gopher service. Then, the next time you log
on, you can view your bookmarks and go directly to that useful site. All Gopher
clients are different, so you need to check the documentation of the system you
are using to know what command to use for bookmarks and other useful Gopher
functions.
Below
is the first screen of the FLTEACH gopher. This will give you an idea of what a
gopher menu looks like. Moving the arrow to the item you want is the way to
select and move through the layers of each menu.
IoT:
The Internet of Things (IoT) refers to a system
of interrelated, internet-connected objects that are able to collect and
transfer data over a wireless network without human intervention.
In an Internet of Things (IoT) ecosystem, two things are very
important: the Internet and physical devices like sensors and actuators. As
shown in Fig. 1, the bottom layer of the IoT system consists of sensor
connectivity and network to collect information. This layer is an essential
part of the IoT system and has network connectivity to the next layer, which is
the gateway and network layer.
Sensors:
The main purpose of sensors is to collect data from the
surrounding environment. Sensors, or ‘things’ of the IoT system, form the front
end. These are connected directly or indirectly to IoT networks after signal
conversion and processing. But all sensors are not the same and different IoT
applications require different types of sensors. For instance, digital sensors
are straightforward and easy to interface with a microcontroller using a Serial
Peripheral Interface (SPI) bus. But for analog sensors, either
analog-to-digital converter (ADC) or Sigma-Delta modulator is used to convert
the data into SPI output.
Actuator:
An actuator is a device that produces a motion
by converting energy and signals going into the system. The motion it produces
can be either rotary or linear.
Features of sensors
Sensors are devices that detect or measure physical or chemical properties of the environment or other systems, and convert them into electrical signals that can be processed by electronic circuits. Some common features of sensors include:
Sensitivity: This refers to the ability of a sensor to detect changes in the measured parameter. A highly sensitive sensor can detect even small changes in the environment or system it is monitoring.
Range: The range of a sensor refers to the minimum and maximum values of the measured parameter that the sensor can detect accurately. For example, a temperature sensor may have a range of -40°C to 125°C.
Accuracy: This refers to how close the sensor's readings are to the true value of the measured parameter. A highly accurate sensor provides more reliable data than a less accurate one.
Precision: Precision refers to how consistently the sensor can measure the same value under the same conditions. A highly precise sensor will produce similar readings for the same measured parameter, while a less precise sensor may produce more variable readings.
Response time: This refers to how quickly a sensor can detect changes in the measured parameter and produce a signal. A faster response time may be important in certain applications, such as in process control systems.
Robustness: Robustness refers to the ability of a sensor to function accurately and reliably under different environmental conditions, such as temperature, humidity, and pressure.
Resolution: Resolution refers to the smallest change in the measured parameter that the sensor can detect. For example, a pressure sensor with a resolution of 0.1 kPa can detect changes as small as 0.1 kPa.
Linearity: This refers to how closely the sensor's output corresponds to changes in the measured parameter. A linear sensor produces a proportional output for proportional changes in the measured parameter, while a non-linear sensor may produce a non-proportional output.
Stability: Stability refers to how well a sensor maintains its accuracy and performance over time. A stable sensor will provide consistent and reliable readings over a long period of time.
Power consumption: This refers to the amount of electrical power that the sensor requires to operate. Low-power sensors may be important in applications where battery life is a concern.
Some common types of IoT sensors
Temperature sensors
These devices measure the amount of heat energy
generated from an object or surrounding area. They find application in
air-conditioners, refrigerators, and similar devices used for environmental
control. They are also used in manufacturing processes, agriculture, and the health
industry.
Temperature sensors can be used almost in every
IoT environment, from manufacturing to agriculture. In manufacturing, sensors
are used to monitor the temperature of machines. In agriculture, these can be
used to monitor the temperature of the soil, water, and plants.
Temperature sensors include thermocouples,
thermistors, resistor temperature detectors (RTDs) and integrated circuits
(ICs)
The amount of water vapour in air, or humidity, can
affect human comfort as well as many manufacturing processes in industries. So
monitoring humidity level is important. Most commonly used units for humidity
measurement are relative humidity (RH), dew/frost point (D/F PT) and parts per
million (PPM).
Motion sensors
Motion sensors are not only used for security purposes
but also in automatic door controls, automatic parking systems, automated
sinks, automated toilet flushers, hand dryers, energy management systems, etc.
You use these sensors in the IoT and monitor them from your smartphone or
computer. HC-SR501 passive infrared (PIR) sensor is a popular motion sensor for
hobby projects.
Gas sensors
These sensors are used to detect toxic gases. The sensing
technologies most commonly used are electrochemical, photo-ionisation and
semiconductor. With technical advancements and new specifications, there are a
multitude of gas sensors available to help extend the wired and wireless
connectivity deployed in IoT applications.
Smoke sensors
Smoke detectors have been in use in homes and industries
for quite a long time. With the advent of the IoT, their application has become
more convenient and user-friendly. Furthermore, adding a wireless connection to
smoke detectors enables additional features that increase safety and
convenience.
These sensors are used in IoT systems to monitor systems
and devices that are driven by pressure signals. When the pressure range is
beyond the threshold level, the device alerts the user about the problems that
should be fixed. For example, BMP180 is a popular digital pressure sensor for
use in mobile phones, PDAs, GPS navigation devices and outdoor equipment.
Pressure sensors are also used in smart vehicles and aircrafts to determine
force and altitude, respectively. In vehicle, tyre pressure monitoring system
(TPMS) is used to alert the driver when tyre pressure is too low and could
create unsafe driving conditions.
Image sensors
These sensors are found in digital cameras, medical
imaging systems, night-vision equipment, thermal imaging devices, radars,
sonars, media house and biometric systems. In the retail industry, these
sensors are used to monitor customers visiting the store through IoT network.
In offices and corporate buildings, they are used to monitor employees and
various activities through IoT networks
IR sensors
An infrared (IR) sensor is an electronic device that
measures and detects infrared radiation in its surrounding environment.
These sensors can measure the heat emitted by objects.
They are used in various IoT projects including healthcare to monitor blood flow
and blood pressure, smartphones to use as remote control and other functions,
wearable devices to detect amount of light, thermometers to monitor temperature
and blind-spot detection in vehicles.
Proximity sensors
These sensors detect the presence or absence of a nearby
object without any physical contact. Different types of proximity sensors are
inductive, capacitive, photoelectric, ultrasonic and magnetic. These are mostly
used in object counters, process monitoring and control.
Smart Cities
Smart cities are urban areas that leverage technology and data to improve the quality of life of their citizens, enhance sustainability, and boost economic growth. They use sensors, data analytics, and other digital technologies to optimize the use of resources and services such as transportation, energy, waste management, and public safety.
Some examples of smart city initiatives include intelligent traffic management systems, energy-efficient buildings, connected public transport, smart waste management, and public Wi-Fi hotspots. By integrating technology into urban planning and management, smart cities aim to reduce costs, enhance efficiency, and create more livable and sustainable urban environments.
However, smart cities also face challenges such as privacy concerns, cybersecurity risks, and potential exclusion of those who may not have access to or be able to afford the necessary technology. Therefore, a balance between technological advancement and equitable access and inclusion must be achieved for smart cities to truly benefit all citizens.
What is the industrial internet of things (IIoT)?
The
industrial internet of things (IIoT) refers to the extension and use of
the internet of things (IoT) in
industrial sectors and applications. With a strong focus on machine-to-machine
(M2M) communication, big data, and machine learning, the IIoT enables
industries and enterprises to have better efficiency and reliability in their
operations. The IIoT encompasses industrial applications, including robotics,
medical devices, and software-defined production processes.
UNIT IV
----------
Hash function demo
A hash function is a mathematical function that converts a numerical input value into another compressed numerical value. The input to the hash function is of arbitrary length but output is always of fixed length.
Hash function properties
1 Fixed Length Output
2 Unique pair of input text and output digest
3 Hashing is a unidirectional process.
What
is Blockchain?
A blockchain is a decentralized, distributed, and oftentimes public, digital ledger consisting of records called blocks that are used to record transactions across many computers so that any involved block cannot be altered retroactively, without the alteration of all subsequent blocks. This allows the participants to verify and audit transactions independently and relatively inexpensively A blockchain database is managed autonomously using a peer-to-peer network and a distributed timestamping server. They are authenticated by mass collaboration powered by collective self-interests
Blockchain can be defined as a chain of blocks that
contains information. The technique is intended to timestamp digital documents
so that it's not possible to backdate them or temper them. The purpose of
blockchain is to solve the double records problem without the need of a central
server.
The blockchain is used for the secure transfer of items like
money, property, contracts, etc. without requiring a third-party intermediary
like bank or government. Once a data is recorded inside a blockchain, it is
very difficult to change it.
The blockchain is a software protocol (like SMTP is for email).
However, Blockchains could not be run without the Internet. It is also called
meta-technology as it affects other technologies. It is comprised of several
pieces: a database, software application, some connected computers, etc.
Sometimes the term used for Bitcoin Blockchain or The Ethereum
Blockchain and sometimes it's other virtual currencies or digital tokens.
However, most of them are talking about the distributed ledgers.
Blockchain
Architecture
Now
in this Blockchain Technology tutorial, let's study the Blockchain architecture
by understanding its various components:
What is a Block?
A
Blockchain is a chain of blocks which contain information. The data which is
stored inside a block depends on the type of blockchain.
For
Example, A Bitcoin Block contains information about the Sender, Receiver,
number of bitcoins to be transferred.
Bitcoin Block
The first block in the
chain is called the Genesis block.
Each new block in the chain is linked to the previous block.
Understanding SHA256 - Hash
A
block also has a hash. A can be understood as a fingerprint which is unique to
each block. It identifies a block and all of its contents, and it's always
unique, just like a fingerprint. So once a block is created, any change inside
the block will cause the hash to change.
Therefore,
the hash is very useful when you want to detect changes to intersections. If the
fingerprint of a block changes, it does not remain the same block.
Each
Block has
- Data
- Hash
- Hash
of the previous block
How Blockchain Transaction Works?
Step 1) Some person requests a transaction. The transaction
could be involved cryptocurrency, contracts, records or other information.
Step 2) The requested transaction is broadcasted to a P2P
network with the help of nodes.
Step 3) The network of nodes validates the transaction and
the user's status with the help of known algorithms.
Step 4) Once the transaction is complete the new block is
then added to the existing blockchain. In such a way that is permanent and
unalterable.
Why
do we need Blockchain?
Here, are some reasons why Blockchain technology has become so
popular.
Time reduction: In the financial industry, blockchain
can play a vital role by allowing the quicker settlement of trades as it does
not need a lengthy process of verification, settlement, and clearance because a
single version of agreed-upon data of the share ledger is available between all
stack holders.
Reliability: Blockchain certifies and verifies the
identities of the interested parties. This removes double records, reducing
rates and accelerates transactions.
Unchangeable
transactions: By registering
transactions in chronological order, Blockchain certifies the unalterability,
of all operations which means when any new block has been added to the chain of
ledgers, it cannot be removed or modified.
Fraud prevention: The concepts of shared information and
consensus prevent possible losses due to fraud or embezzlement. In
logistics-based industries, blockchain as a monitoring mechanism act to reduce
costs.
Security: Attacking a traditional database is the
bringing down of a specific target. With the help of Distributed Ledger
Technology, each party holds a copy of the original chain, so the system
remains operative, even the large number of other nodes fall.
Transparency: Changes to public blockchains are
publicly viewable to everyone. This offers greater transparency, and all
transactions are immutable.
Collaboration – Allows parties to transact directly with
each other without the need for mediating third parties.
Decentralized: There are standards rules on how every
node exchanges the blockchain information. This method ensures that all
transactions are validated, and all valid transactions are added one by one.
What Is a Cryptocurrency?
A cryptocurrency is a digital or virtual currency that is secured by cryptography, which makes it
nearly impossible to counterfeit or double-spend. Many cryptocurrencies are
decentralized networks based on blockchain technology—a distributed ledger enforced by a
disparate network of computers. A defining feature of cryptocurrencies is that
they are generally not issued by any central authority, rendering them
theoretically immune to government interference or manipulation.
KEY
TAKEAWAYS
- A
cryptocurrency is a new form of digital asset based on a network that is
distributed across a large number of computers. This decentralized
structure allows them to exist outside the control of governments and
central authorities.
- The
word “cryptocurrency” is derived from the encryption techniques which are
used to secure the network.
- Blockchains,
which are organizational methods for ensuring the integrity of
transactional data, is an essential component of many cryptocurrencies.
- Many
experts believe that blockchain and related technology will disrupt many
industries, including finance and law.
- Cryptocurrencies face criticism for a number of
reasons, including their use for illegal activities, exchange rate
volatility, and vulnerabilities of the infrastructure underlying them.
However, they also have been praised for their portability, divisibility,
inflation resistance, and transparency.
Understanding Cryptocurrencies
Cryptocurrencies are systems that allow for the secure
payments online which are denominated in terms of virtual "tokens,"
which are represented by ledger entries internal to the system.
"Crypto" refers to the various encryption algorithms and
cryptographic techniques that safeguard these entries, such as elliptical curve
encryption, public-private key pairs, and hashing functions.
Types of Cryptocurrency
The first blockchain-based cryptocurrency was Bitcoin, which still remains the most popular and most valuable.
Today, there are thousands of alternate cryptocurrencies with various functions
and specifications. Some of these are clones or forks of Bitcoin, while others are new currencies that
were built from scratch.
Bitcoin was launched in 2009 by an individual or group
known by the pseudonym "Satoshi Nakamoto."1 As of Nov. 2019, there were over 18 million
bitcoins in circulation with a total market value of around $146 billion.2
Some of the competing cryptocurrencies spawned by
Bitcoin’s success, known as "altcoins," include Litecoin, Peercoin, and Namecoin, as well as Ethereum, Cardano, and EOS. Today, the aggregate value of all the cryptocurrencies in existence
is around $214 billion—Bitcoin currently represents more than 68% of the total
value.
Advantages and Disadvantages of
Cryptocurrency
Advantages
Cryptocurrencies hold the promise of making it easier to
transfer funds directly between two parties, without the need for a trusted
third party like a bank or credit card company. These transfers are instead secured by the use of public keys and private keys and different forms of incentive systems,
like Proof of Work or Proof of Stake.
In modern cryptocurrency systems, a user's "wallet," or account address, has a public key, while the
private key is known only to the owner and is used to sign transactions. Fund
transfers are completed with minimal processing fees, allowing users to avoid
the steep fees charged by banks and financial
institutions for wire transfers.
Disadvantages
The semi-anonymous nature of cryptocurrency transactions
makes them well-suited for a host of illegal activities, such as money laundering and tax evasion. However, cryptocurrency advocates often highly value
their anonymity, citing benefits of privacy like protection for whistleblowers
or activists living under repressive governments. Some cryptocurrencies are
more private than others.
Bitcoin, for instance, is a relatively poor choice for
conducting illegal business online, since the forensic analysis of the Bitcoin
blockchain has helped authorities to arrest and prosecute criminals. More
privacy-oriented coins do exist, however, such as Dash, Monero, or ZCash, which are far more difficult to trace.
other useful link
BlockChain Explain
BlockChain.com
Features of
block chain
Blockchain is a distributed digital ledger technology that
allows secure, transparent, and tamper-proof recording of transactions and
data. Some of the key features of blockchain include:
Decentralization: Blockchain is a decentralized system,
meaning there is no central authority controlling it. It is distributed across
a network of nodes, and each node has a copy of the ledger.
Immutability: Once a transaction is recorded on the blockchain,
it cannot be altered or deleted. This makes blockchain a highly secure and
tamper-proof technology.
Transparency: All the transactions on the blockchain are
transparent and visible to all the nodes in the network. This allows for
greater accountability and reduces the risk of fraud.
Security: Blockchain uses cryptographic algorithms to ensure
the security of data and transactions. This makes it highly resistant to
hacking and other malicious activities.
Smart Contracts: Blockchain supports the creation and
execution of smart contracts, which are self-executing contracts with the terms
of the agreement directly written into lines of code.
Speed: Blockchain transactions can be processed quickly,
especially compared to traditional banking and financial systems.
Cost-effectiveness: Blockchain eliminates the need for
intermediaries such as banks, lawyers, and other third-party service providers,
which can reduce costs and increase efficiency.
Privacy: While blockchain transactions are transparent, the
identity of the parties involved can be kept private through the use of
cryptographic techniques.
Limitations
of Block chain
Blockchain is a powerful technology that has revolutionized
various industries, but it also has some limitations. Some of the limitations
of blockchain are:
Scalability: Blockchain technology can be slow and
inefficient, especially when it comes to processing a large number of
transactions. As the size of the blockchain grows, it can become challenging to
maintain a decentralized network of nodes, which can cause delays in
transaction processing.
Energy Consumption: One of the significant concerns with
blockchain is the high energy consumption required for mining and validating
transactions. The proof-of-work consensus mechanism used in many blockchain
networks requires significant computational power, which consumes a
considerable amount of energy.
Lack of Governance: Blockchain is a decentralized technology
that operates without a centralized authority. While this is one of its
strengths, it can also be a weakness as it can be challenging to make changes
or upgrades to the network without consensus from all nodes. This can result in
slow decision-making and can limit the ability to adapt to changing
circumstances.
Security: While blockchain technology is considered to be
highly secure due to its distributed and immutable nature, it is not entirely immune
to security breaches. In some cases, hackers have been able to exploit
vulnerabilities in the system to steal cryptocurrency or disrupt the network.
Adoption: Despite the potential benefits of blockchain,
adoption remains a significant challenge. The technology is still in its early
stages, and many businesses and individuals are not yet familiar with its
capabilities or benefits. Additionally, there are regulatory challenges that
can make it difficult to implement blockchain-based solutions in certain
industries.
Application
areas and fundamentals of block chain
Blockchain is a distributed ledger technology that allows
for secure and transparent transactions without the need for intermediaries.
The fundamental components of a blockchain include blocks, which contain data
and a unique cryptographic hash, and a consensus mechanism that ensures that
all participants in the network agree on the state of the ledger.
Here are some application areas of blockchain technology:
Cryptocurrencies: Blockchain is the underlying technology
behind cryptocurrencies like Bitcoin, Ethereum, and others. It allows for
secure and transparent transactions without the need for intermediaries like
banks or financial institutions.
Supply chain management: Blockchain can be used to track and
trace products as they move through the supply chain. This can help to ensure
the authenticity and provenance of products, and prevent fraud and
counterfeiting.
Identity verification: Blockchain can be used to create
secure and decentralized identity verification systems that allow individuals
to prove their identity without the need for a central authority.
Voting systems: Blockchain can be used to create secure and
transparent voting systems that prevent tampering and ensure the integrity of
elections.
Smart contracts: Blockchain can be used to create
self-executing smart contracts that automatically execute when certain
conditions are met. This can be used in a variety of industries, including
finance, insurance, and real estate.
The fundamental principles of block chain technology
include:
Decentralization: Block chain is a decentralized technology,
meaning that it does not rely on a central authority to manage the ledger.
Instead, the ledger is distributed across a network of computers, and all
participants have a copy of the ledger.
Security: Block chain is a secure technology, thanks to the
use of cryptographic algorithms to secure the ledger. Each block in the chain
is linked to the previous block, making it virtually impossible to tamper with
the data.
Transparency: Blockchain is a transparent technology,
meaning that all participants in the network can see the transactions on the
ledger. This helps to prevent fraud and increases accountability.
Immutability: Once a block is added to the blockchain, it
cannot be altered or deleted. This makes the blockchain a permanent and
tamper-proof record of transactions.
Crypto
Use-Cases.
Application and use-cases of cryptocurrency
Cryptocurrency is a digital asset designed to work as a
medium of exchange that uses strong cryptography to secure financial
transactions, control the creation of additional units, and verify the transfer
of assets. Some of the most popular cryptocurrencies include Bitcoin, Ethereum,
Litecoin, and Ripple.
There are many potential applications and use-cases for
cryptocurrency, including:
Online Payments: Cryptocurrencies can be used to make online
purchases and payments, as they provide a secure and efficient way to transfer
funds without the need for intermediaries like banks or credit card companies.
International Money Transfers: Cryptocurrencies can be used
to send money across borders without the need for expensive wire transfers or
currency conversions. This is especially useful for people who live in
countries with strict capital controls or high remittance fees.
Investment: Cryptocurrencies can be used as a speculative
investment, as their value can fluctuate significantly over time. Investors can
buy and hold cryptocurrencies in the hopes of selling them for a profit later
on.
Decentralized Finance: Cryptocurrencies can be used as part
of a decentralized finance (DeFi) ecosystem, which allows users to access
financial services without the need for traditional banks or financial
institutions.
Smart Contracts: Some cryptocurrencies, such as Ethereum,
allow for the creation of smart contracts, which are self-executing contracts
with the terms of the agreement directly written into lines of code. This can
be used for a variety of applications, including digital identity verification,
voting systems, and supply chain management.
Gaming: Cryptocurrencies can be used as in-game currencies
in online games, allowing for seamless and secure transactions between players.
Overall, cryptocurrency has the potential to revolutionize the
way we think about money, finance, and online transactions. As the technology
continues to evolve, it is likely that we will see many more innovative
use-cases for cryptocurrencies in the years to come.
Cloud Computing
What is cloud computing, in simple terms?
Cloud
computing is the delivery of on-demand computing services -- from applications
to storage and processing power -- typically over the internet and on a
pay-as-you-go basis.
How does cloud computing work?
Rather
than owning their own computing infrastructure or data centers, companies can
rent access to anything from applications to storage from a cloud service
provider.
One benefit
of using cloud computing services is that firms can avoid the upfront cost and
complexity of owning and maintaining their own IT infrastructure, and instead
simply pay for what they use, when they use it.
In turn,
providers of cloud computing services can benefit from significant economies of
scale by delivering the same services to a wide range of customers.
What cloud computing services are available?
Cloud computing services cover a vast range of
options now, from the basics of storage, networking, and processing power
through to natural language processing and artificial intelligence as well as
standard office applications. Pretty much any service that doesn't require you
to be physically close to the computer hardware that you are using can now be
delivered via the cloud.
Infrastructure-as-a-Service
Cloud computing can be broken down into three cloud
computing models. Infrastructure-as-a-Service (IaaS) refers to the fundamental
building blocks of computing that can be rented: physical or virtual servers,
storage and networking. This is attractive to companies that want to build
applications from the very ground up and want to control nearly all the
elements themselves, but it does require firms to have the technical skills to
be able to orchestrate services at that level. Research by Oracle found that
two thirds of IaaS users said using online infrastructure makes it easier to
innovate, had cut their time to deploy new applications and services and had
significantly cut on-going maintenance costs. However, half said IaaS isn't secure enough for
most critical data.
popular example Rackspace. Amazon Web Services (AWS) Cisco Metacloud. Microsoft Azure
Platform-as-a-Service
Platform-as-a-Service
(PaaS) is the next layer up -- as well as the underlying storage, networking,
and virtual servers this will also include the tools and software that
developers need to build applications on top of: that could include middleware,
database management, operating systems, and development tools.
· Popular examples of PaaS include Quickbase, AWS Elastic Beanstalk, and Boomi.
Insight
platforms as a service: What they are and why they matter
Software-as-a-Service
Microsoft 365
(formerly Office 365) for business: Everything you need to know
Microsoft's
multitude of Business and Enterprise editions -- licensed as monthly or annual
subscriptions -- offer more advanced feature sets than the Home and Personal
editions, with collaborative applications and management tools designed for
meeting enterprise security and compliance challenges.
Software-as-a-Service
(SaaS) is the delivery of applications-as-a-service, probably the version of
cloud computing that most people are used to on a day-to-day basis. The
underlying hardware and operating system is irrelevant to the end user, who
will access the service via a web browser or app; it is often bought on a
per-seat or per-user basis.
According to researchers IDC SaaS is -- and will remain
-- the dominant cloud computing model in
the medium term, accounting for two-thirds of all public cloud spending in
2017, which will only drop slightly to just under 60% in 2021. SaaS spending is
made up of applications and system infrastructure software, and IDC said that
spending will be dominated by applications purchases, which will make up more
than half of all public cloud spending through 2019. Customer relationship
management (CRM) applications and enterprise resource management (ERM)
applications will account for more than 60% of all cloud applications spending
through to 2021. The variety of applications delivered via SaaS is huge, from
CRM such as Salesforce through to Microsoft's Office 365.
SaaS is easily the most popular form of cloud computing. Gmail, Slack, and Microsoft Office 365
Nature and
benefits of cloud computing
Cloud computing is the delivery of on-demand computing
resources over the internet, such as servers, storage, applications, and
services. Instead of businesses and individuals having to buy, maintain, and
upgrade their own hardware and software, they can access these resources
through a cloud provider on a pay-as-you-go basis. The benefits of cloud
computing are numerous and include:
Cost Savings: Cloud computing eliminates the need for
businesses and individuals to invest in expensive hardware and software,
reducing capital expenditure.
Scalability: Cloud computing allows businesses to scale up
or down their computing resources as needed, without the need for additional
hardware and software.
Reliability: Cloud providers typically offer a high level of
uptime and availability, ensuring that resources are always accessible.
Flexibility: Cloud computing allows businesses to access
resources from anywhere with an internet connection, making it easy to work
remotely and collaborate with others.
Security: Cloud providers often have extensive security
measures in place to protect against data breaches and cyber threats.
Disaster Recovery: Cloud computing provides businesses with
a reliable backup and recovery solution in case of a disaster or outage.
Overall, cloud computing provides businesses and individuals
with a cost-effective, scalable, flexible, and reliable way to access computing
resources, without the need for costly hardware and software investments.
Cloud
Computing Platforms.
Short notes on AWS ,google, Microsoft and IBM services
AWS (Amazon Web Services) is a cloud computing platform
offered by Amazon. It offers a wide range of services including computing,
storage, databases, analytics, machine learning, networking, security, and
more. Some popular AWS services include Amazon EC2, Amazon S3, Amazon RDS, and
Amazon Lambda.
Google Cloud Platform is a suite of cloud computing services
offered by Google. It offers a range of services including compute, storage,
databases, analytics, machine learning, networking, and more. Popular Google
Cloud Platform services include Google Compute Engine, Google Cloud Storage,
and Google BigQuery.
Microsoft Azure is a cloud computing platform offered by
Microsoft. It offers a range of services including compute, storage, databases,
analytics, machine learning, networking, and more. Popular Microsoft Azure
services include Azure Virtual Machines, Azure Storage, and Azure SQL Database.
IBM Cloud is a cloud computing platform offered by IBM. It
offers a range of services including compute, storage, databases, analytics,
machine learning, networking, and more. Popular IBM Cloud services include IBM
Watson Studio, IBM Cloud Object Storage, and IBM Cloud Kubernetes Service.
All of these cloud computing platforms offer similar
services, but each has its own unique features and strengths. Customers should
evaluate the specific needs of their organization to determine which cloud
computing platform is best suited for their needs.
UNIT V
----------
What is Big Data?
Big Data is a term used for a collection of data
sets that are large and complex, which is difficult to store and process
using available database management tools or traditional data processing
applications. The challenge includes capturing, curating, storing, searching,
sharing, transferring, analyzing and visualization of this data.
Big Data Characteristics
The five characteristics that define Big Data are:
Volume, Velocity, Variety, Veracity and Value.
1.
VOLUME
Volume refers to the ‘amount of data’, which is
growing day by day at a very fast pace. The size of data generated by humans,
machines and their interactions on social media itself is massive.
Researchers have predicted that 40 Zettabytes (40,000 Exabytes) will be
generated by 2020, which is an increase of 300 times from 2005.
2.
VELOCITY
Velocity is defined as the pace at which different
sources generate the data every day. This flow of data is massive and
continuous. There are 1.03 billion Daily Active Users (Facebook DAU) on Mobile
as of now, which is an increase of 22% year-over-year. This shows how fast the
number of users are growing on social media and how fast the data is getting
generated daily. If you are able to handle the velocity, you will be able to
generate insights and take decisions based on real-time data.
3.
VARIETY
As there are many sources which are contributing to
Big Data, the type of data they are generating is different. It can be
structured, semi-structured or unstructured. Hence, there is a variety of data
which is getting generated every day. Earlier, we used to get the data
from excel and databases, now the data are coming in the form of images,
audios, videos, sensor data etc. as shown in below image. Hence, this
variety of unstructured data creates problems in capturing, storage, mining and
analyzing the data.
4.
VERACITY
Veracity refers to the data in doubt or uncertainty
of data available due to data inconsistency and
incompleteness. In the image below, you can see that few values are
missing in the table. Also, a few values are hard to accept, for example –
15000 minimum value in the 3rd row, it is not possible. This inconsistency
and incompleteness is Veracity.
Data available can sometimes get messy and maybe
difficult to trust. With many forms of big data, quality and accuracy are
difficult to control like Twitter posts with hashtags, abbreviations, typos and
colloquial speech. The volume is often the reason behind for the lack of
quality and accuracy in the data.
·
Due to uncertainty of data, 1 in 3
business leaders don’t trust the information they use to make decisions.
·
It was found in a survey that 27% of
respondents were unsure of how much of their data was inaccurate.
·
Poor data quality costs the US economy
around $3.1 trillion a year.
5.
VALUE
After discussing Volume, Velocity, Variety and
Veracity, there is another V that should be taken into account when looking at
Big Data i.e. Value. It is all well and good to have access to big data but
unless we can turn it into value it is useless. By turning it into value I
mean, Is it adding to the benefits of the organizations who are analyzing
big data? Is the organization working on Big Data achieving high
ROI (Return On Investment)? Unless, it adds to their profits by working on Big
Data, it is useless.
As discussed in Variety, there are different types
of data which is getting generated every day. So, let us now
understand the types of data:
Types of Big Data
Big Data could be of three types:
- Structured
- Semi-Structured
- Unstructured
- Structured
The data that can be stored and processed in a fixed
format is called as Structured Data. Data stored in a relational database
management system (RDBMS) is one example of ‘structured’ data. It is easy
to process structured data as it has a fixed schema. Structured Query Language
(SQL) is often used to manage such kind of Data.
- Semi-Structured
Semi-Structured Data is a type of data which does
not have a formal structure of a data model, i.e. a table definition in a
relational DBMS, but nevertheless it has some organizational properties like
tags and other markers to separate semantic elements that makes it easier to
analyze. XML files or JSON documents are examples of semi-structured data.
- Unstructured
The data which have unknown form and cannot be
stored in RDBMS and cannot be analyzed unless it is transformed into a
structured format is called as unstructured data. Text Files and multimedia
contents like images, audios, videos are example of unstructured data. The
unstructured data is growing quicker than others, experts say that 80 percent
of the data in an organization are unstructured.
Till now, I have just covered the introduction
of Big Data. Furthermore, this Big Data tutorial talks about examples,
applications and challenges in Big Data.
Examples of Big Data
Daily we upload millions of bytes of data. 90 % of
the world’s data has been created in last two years.
- Walmart
handles more than 1 million customer transactions every hour.
- Facebook
stores, accesses, and analyzes 30+ Petabytes of user generated
data.
- 230+
millions of tweets are created every day.
- More
than 5 billion people are calling, texting, tweeting and browsing
on mobile phones worldwide.
- YouTube
users upload 48 hours of new video every minute of the day.
- Amazon
handles 15 million customer click stream user data per day to
recommend products.
- 294
billion emails are sent every day.
Services analyses this data to find the spams.
- Modern
cars have close to 100 sensors which monitors fuel level, tire
pressure etc. , each vehicle generates a lot of sensor data.
Applications of Big Data
We cannot talk about data without talking about the
people, people who are getting benefited by Big Data applications. Almost all
the industries today are leveraging Big Data applications in one or the
other way.
- Smarter
Healthcare: Making use of the petabytes of
patient’s data, the organization can extract meaningful information and
then build applications that can predict the patient’s deteriorating
condition in advance.
- Telecom:
Telecom sectors collects information, analyzes it and provide solutions to
different problems. By using Big Data applications, telecom companies have
been able to significantly reduce data packet loss, which occurs when
networks are overloaded, and thus, providing a seamless connection to their
customers.
- Retail:
Retail has some of the tightest margins, and is one of the greatest
beneficiaries of big data. The beauty of using big data in retail is to
understand consumer behavior. Amazon’s recommendation engine provides
suggestion based on the browsing history of the consumer.
- Traffic
control: Traffic congestion is a major
challenge for many cities globally. Effective use of data and sensors will
be key to managing traffic better as cities become increasingly densely
populated.
- Manufacturing:
Analyzing big data in the manufacturing industry can reduce component
defects, improve product quality, increase efficiency, and save time and
money.
- Search
Quality: Every time we are extracting
information from google, we are simultaneously generating data for
it. Google stores this data and uses it to improve its search quality.
Someone has rightly said: “Not everything
in the garden is Rosy!”. Till now in this Big Data tutorial, I
have just shown you the rosy picture of Big Data. But if it was so easy to
leverage Big data, don’t you think all the organizations would invest in it?
Let me tell you upfront, that is not the case. There are several challenges
which come along when you are working with Big Data.
Now that you are familiar with Big Data and its
various features, the next section of this blog on Big Data Tutorial will shed
some light on some of the major challenges faced by Big Data.
Challenges with Big Data
Let me tell you few challenges which come along with
Big Data:
- Data
Quality – The problem here is the 4th
V i.e. Veracity. The data here is very messy, inconsistent and
incomplete. Dirty data cost $600 billion to the companies every year in
the United States.
- Discovery
– Finding insights on Big Data is like finding a needle in a
haystack. Analyzing petabytes of data using extremely powerful
algorithms to find patterns and insights are very difficult.
- Storage
– The more data an organization has, the more complex the problems of
managing it can become. The question that arises here is “Where to store
it?”. We need a storage system which can easily scale up or down
on-demand.
- Analytics
– In the case of Big Data, most of the time we are unaware of the kind of
data we are dealing with, so analyzing that data is even more difficult.
- Security
– Since the data is huge in size, keeping it secure is another challenge.
It includes user authentication, restricting access based on a user,
recording data access histories, proper use of data encryption etc.
- Lack
of Talent – There are a lot of Big Data
projects in major organizations, but a sophisticated team of developers,
data scientists and analysts who also have sufficient amount of domain
knowledge is still a challenge.
Augmented Reality
What Is Augmented Reality?
Augmented
reality (AR) is an enhanced version of the real physical world that is achieved
through the use of digital visual elements, sound, or other sensory stimuli
delivered via technology. It is a growing trend among companies involved in
mobile computing and business applications in particular.
Amid
the rise of data collection and
analysis, one of augmented reality’s primary goals is to highlight specific
features of the physical world, increase understanding of those features, and
derive smart and accessible insight that can be applied to real-world
applications. Such big data can help inform companies' decision-making and gain
insight into consumer spending habits,
among others.
KEY TAKEAWAYS
- Augmented reality (AR) involves
overlaying visual, auditory, or other sensory information onto the world
in order to enhance one's experience.
- Retailers and other companies can use
augmented reality to promote products or services, launch novel marketing
campaigns, and collect unique user data.
- Unlike virtual reality, which
creates its own cyber environment, augmented reality adds to the existing
world as it is.
Understanding Augmented Reality
Augmented
reality continues to develop and become more pervasive among a wide range of
applications. Since its conception, marketers and technology firms
have had to battle the perception that augmented reality is little more than a
marketing tool. However, there is evidence that consumers are beginning to
derive tangible benefits from this functionality and expect it as part of
their purchasing process.
For
example, some early adopters in
the retail sector have developed technologies that are designed to enhance the
consumer shopping experience. By incorporating augmented reality into catalog
apps, stores let consumers visualize how different products would look like in
different environments. For furniture, shoppers point the camera at the
appropriate room and the product appears in the foreground.
Elsewhere,
augmented reality’s benefits could extend to the healthcare sector,
where it could play a much bigger role. One way would be through apps that
enable users to see highly detailed, 3D images of different body systems when
they hover their mobile device over a target image. For example, augmented
reality could be a powerful learning tool for medical professionals throughout
their training.
Some
experts have long speculated that wearable devices
could be a breakthrough for augmented reality. Whereas smartphones and
tablets show a tiny portion of the user’s landscape, smart eyewear, for example,
may provide a more complete link between real and virtual realms if it develops
enough to become mainstream.
Categories of AR Apps and Examples
a) Augmented Reality in 3D viewers:
AUGMENT
Sun-Seeker
b) Augmented Reality in Browsers:
ARGON4
AR Browser SDK
c) Augmented Reality Games:
Pokémon Go
REAL STRIKE
d) Augmented Reality GPS:
AR GPS Drive/Walk Navigation
AR GPS Compass Map 3D
Other example :Hololens ,Google ARCore, Google Glass
Limitations of augmented reality
Augmented reality (AR) is a technology that superimposes computer-generated content onto the real world, allowing users to interact with both the virtual and physical environments simultaneously. However, like any technology, AR also has its limitations. Some of the limitations of augmented reality are:
Limited field of view: AR devices have a limited field of view, which means that only a small portion of the real world can be augmented at a time. This can be a hindrance to some applications, such as gaming or navigation, where a wider field of view would be useful.
Technical complexity: Developing AR applications requires specialized knowledge and expertise, which can make it difficult for non-technical users to create AR content.
Hardware requirements: AR experiences require hardware such as cameras, sensors, and displays, which can be expensive and may limit the accessibility of AR to some users.
Battery life: AR applications require a lot of processing power, which can drain the battery life of mobile devices quickly. This can be a significant problem for users who need to use AR applications for extended periods.
Environmental factors: AR experiences can be affected by environmental factors such as lighting, shadows, and reflections, which can impact the quality and accuracy of the AR content.
User experience: AR experiences require users to hold their devices up in front of them for extended periods, which can be tiring and uncomfortable. The user experience can also be affected by factors such as the quality of the camera, the speed of the processing, and the accuracy of the tracking.
What Is Virtual Reality?
Virtual
reality (VR) refers to a computer-generated simulation in which a person can
interact within an artificial three-dimensional environment using electronic
devices, such as special goggles with a
screen or gloves fitted with sensors. In this
simulated artificial environment, the user is able to have a realistic-feeling
experience.
Augmented reality (AR)
is different from VR, in that AR enhances the real world as it exists with
graphical overlays and does not create a fully immersive experience
KEY TAKEAWAYS
- Virtual reality (VR) creates an
immersive artificial world that can seem quite real, via the use of
technology.
- Through a virtual reality viewer,
users can look up, down, or any which way, as if they were actually there.
- Virtual reality has many use-cases,
including entertainment and gaming, or acting as a sales, educational, or
training tool.
Understanding
Virtual Reality
·
The
concept of virtual reality is built on the natural combination of two
words: the virtual and the real. The former means "nearly" or
"conceptually," which leads to an experience that is
near-reality through the use of technology. Software creates and serves up
virtual worlds that are experienced by users who wear hardware devices such as
goggles, headphones, and special gloves. Together, the user can view and
interact with the virtual world as if from within.
·
To
understand virtual reality, let's draw a parallel with real-world observations.
We understand our surroundings through our senses and the perception mechanisms
of our body. Senses include taste, touch, smell, sight, and hearing, as well as
spatial awareness and balance. The inputs gathered by these senses are
processed by our brains to make interpretations of the objective environment
around us. Virtual reality attempts to create an illusory environment that
can be presented to our senses with artificial information, making our minds
believe it is (almost) a reality.
Augmented Reality vs. Virtual Reality
Augmented reality uses the existing real-world environment and puts virtual information on top of it to enhance the experience.
In contrast, virtual reality immerses users, allowing them to "inhabit" an entirely different environment altogether, notably a virtual one created and rendered by computers. Users may be immersed in an animated scene or an actual location that has been photographed and embedded in a virtual reality app. Through a virtual reality viewer, users can look up, down, or any which way, as if they were actually there.
Grid Computing
Grid Computing can be defined as a network of
computers working together to perform a task that would rather be difficult for
a single machine. All machines on that network work under the same protocol to
act as a virtual supercomputer. The task that they work on may include
analyzing huge datasets or simulating situations that require high computing
power. Computers on the network contribute resources like processing power and
storage capacity to the network
Grid Computing is a subset of distributed
computing, where a virtual supercomputer comprises machines on a network
connected by some bus, mostly Ethernet or sometimes the Internet. It can also
be seen as a form of Parallel
Computing where
instead of many CPU cores on a single machine, it contains multiple cores
spread across various locations. The concept of grid computing isn’t new, but
it is not yet perfected as there are no standard rules and protocols
established and accepted by people.
Working:
A Grid computing network mainly consists of these three types of machines
1.
Control Node:
A computer, usually a server or a group of servers administrates the
whole network and keeps the account of the resources in the network pool.
2.
Provider:
The computer contributes its resources to the network resource pool.
3.
User:
The computer that uses the resources on the network.
When a computer makes a request for
resources to the control node, the control node gives the user access to the
resources available on the network. When it is not in use it should ideally
contribute it’s resources to the network. Hence a normal computer on the node
can swing in between being a user or a provider based on it’s needs. The nodes
may consist of machines with similar platforms using same OS called homogenous
networks, else machines with different platforms running on various different
OS called heterogenous networks. This is the distinguishing part of grid
computing from other distributed computing architectures.
For
controlling the network and it’s resources a software/networking protocol is
used generaly known as Middleware. This is responsible for administrating
the network and the control nodes are merely it’s executors. As a grid
computing system should use only unused resources of a computer, it is the job
of the control node that any provider is not overloaded with tasks.
Another
job of the middleware is to authorize any process that is being executed on the
network. In a grid computing system, a provider gives permission to the user to
run anything on it’s computer, hence it is a huge security threat for the
network. Hence a middleware should ensure that there is no unwanted task being
executed on the network.
Advantages
of Grid Computing:
1.
It
is not centralized, as there are no servers required, except the control node
which is just used for controlling and not for processing.
2.
Multiple
heterogenous machines i.e. machines with different Operating Systems can use a
single grid computing network.
3.
Tasks
can be performed parallely accross various physical locations and the users
don’t have to pay for it(with money).
Green computing
Green
computing, also called green technology, is the environmentally responsible use
of computers and related resources. Such practices include the implementation
of energy-efficient central processing units (CPUs), servers and peripherals as well as
reduced resource consumption and proper disposal of electronic waste (e-waste).
One of the
earliest initiatives toward green computing in the United States was the
voluntary labeling program known as Energy Star. It was conceived by the Environmental
Protection Agency (EPA) in 1992 to promote energy efficiency in hardware of all
kinds. The Energy Star label became a common sight, especially in notebook computers and displays. Similar programs have been adopted in
Europe and Asia.
Government
regulation, however well-intentioned, is only part of an overall green
computing philosophy. The work habits of computer users and businesses can be
modified to minimize adverse impact on the global environment. Here are some
steps that can be taken:
·
Power-down
the CPU and all peripherals during extended periods of inactivity.
·
Try
to do computer-related tasks during contiguous, intensive blocks of time,
leaving hardware off at other times.
·
Power-up
and power-down energy-intensive peripherals such as laser printers according to
need.
·
Use
liquid-crystal-display (LCD) monitors rather than
cathode-ray-tube (CRT) monitors.
·
Use
notebook computers rather than desktop computers whenever
possible.
·
Use
the power-management features to turn off hard drives and displays
after several minutes of inactivity.
·
Minimize
the use of paper and properly recycle waste paper.
·
Dispose
of e-waste according to federal, state, and local regulations.
·
Employ
alternative energy sources for computing workstations,
servers, networks and data centers.
Quantum Computing
·
Quantum
computers are machines that use the properties of quantum physics to store data and perform
computations. This can be extremely advantageous for certain tasks where they
could vastly outperform even our best supercomputers.
·
Classical
computers, which include smartphones and laptops, encode information in binary
“bits” that can either be 0s or 1s. In a quantum computer, the basic unit of memory is a quantum bit
or qubit.
·
Qubits
are made using physical systems, such as the spin of an electron or the
orientation of a photon. These systems can be in many different arrangements
all at once, a property known as quantum superposition. Qubits can also be inextricably
linked together using a phenomenon called quantum entanglement. The result is that a series of qubits can
represent different things simultaneously.
·
For
instance, eight bits is enough for a classical computer to represent any number
between 0 and 255. But eight qubits is enough for a quantum computer to
represent every number between 0 and 255 at the same time. A few hundred
entangled qubits would be enough to represent more numbers than there are atoms
in the universe.
·
This
is where quantum computers get their edge over classical ones. In situations
where there are a large number of possible combinations, quantum computers can
consider them simultaneously. Examples include trying to find the prime factors
of a very large number or the best route between two places.
·
However,
there may also be plenty of situations where classical computers will still
outperform quantum ones. So the computers of the future may be a combination of
both these types.
·
For
now, quantum computers are highly sensitive: heat, electromagnetic fields and
collisions with air molecules can cause a qubit to lose its quantum properties.
This process, known as quantum decoherence, causes the system to crash, and it
happens more quickly the more particles that are involved.
·
Quantum
computers need to protect qubits from external interference, either by
physically isolating them, keeping them cool or zapping them with carefully
controlled pulses of energy. Additional qubits are needed to correct for errors
that creep into the system.
Brain-Computer
Interface (BCI)
A Brain-Computer
Interface (BCI) is a technology that allows a human to control a computer,
peripheral or other electronic device with thought. • It does so by using
electrodes to detect electric signals in the brain which are sent to a
computer. • The computer then translates these electric signals into data which
is used to control a computer or a device linked to a computer.
How
the brain turns thoughts into action?
The brain is full of
neurons; these neurons are connected to each other by axons and dendrites. •
Your neurons - as you think about anything or do anything - are at work. • Your
neurons connect with each other to form a super highway for nerve impulses to
travel from neuron to neuron to produce thought, hearing, speech, or movement.
• If you have an itch and you reach to scratch it; you received a stimulus (an
itch) and reacted in response to the stimulus by scratching. • The electrical
signals that generated the thought and action travel at a rate of about 250
feet per second or faster, in some cases.
Interface
The easiest and least
invasive method is a set of electrodes -- a device known as an
electroencephalograph (EEG) -- attached to the scalp. The electrodes can read
brain signals. To get a higher-resolution signal, scientists can implant
electrodes directly into the gray matter of the brain itself, or on the surface
of the brain, beneath the skull.
Applications
• Provide disabled
people with communication, environment control, and movement restoration.
• Provide enhanced
control of devices such as wheelchairs, vehicles, or assistance robots for
people with disabilities.
• Provide additional
channel of control in computer games.
• Monitor attention in long-distance drivers
or aircraft pilots, send out alert and warning for aircraft pilots.
• Develop intelligent
relaxation devices.
Advantages
of BCI
Eventually, this
technology could:
• Allow paralyzed
people to control prosthetic limbs with their mind.
• Transmit visual
images to the mind of a blind person, allowing them to see.
• Transmit auditory data to the mind of a deaf
person, allowing them to hear.
• Allow gamers to control video games with
their minds.
• Allow a mute person
to have their thoughts displayed and spoken by a computer
Disadvantages
of BCI
• Research is still in
beginning stages.
• The current
technology is crude.
• Ethical issues may
prevent its development.
• Electrodes outside of
the skull can detect very few electric signals from the brain.
• Electrodes placed
inside the skull create scar tissue in the brain.
Conclusion
As BCI technology
further advances, brain tissue may one day give way to implanted silicon chips
thereby creating a completely computerized simulation of the human brain that
can be augmented at will. Futurists predict that from there, superhuman
artificial intelligence won't be far behind.
------------------------------------------------
Exercise
https://www.sanfoundry.com/1000-computer-fundamentals-questions-answers/
-----------------------------------------------